
Mit einfachen Mitteln einen Singer/Songwriter aufnehmen? In diesem Workshop erfährst Du online, wie Akustikgitarre und Gesang mikrofoniert werden können – und noch mehr!

Die Singer/Songwriter-Tradition ist aus der Popmusik nicht wegzudenken. Seit jeher drücken sich zahlreiche Künstler mit ihrem Gesang und eigenen Songs aus und begleiten sich dabei selbst auf einem Instrument. Ich für meinen Teil verbinde mit dem Begriff ‚Singer/Songwriter’ vor allem Musiker, die ihren Gesang auf einer Gitarre begleiten. Ganz gleich ob ein Musiker wie Bob Dylan aus der Traditional/Folk-Richtung komm oder eher in der moderneren Coffeehouse-Ecke anzusiedeln ist, wie beispielsweise Jack Johnson.
Singer/Songwriter und ihre Gitarre umgibt stets ein Flair von musikalischer Authentizität, lyrischem Feingeist und staubigem „On-The-Road“-Flair. Doch wie lassen sich Gitarre und Vocals so aufnehmen und bearbeiten, dass sich diese Charakteristika auch im selbstproduzierten Track wiederfinden? Um diese und noch ein paar weitere Fragen zu klären, schauen wir uns in diesem Workshop an, wie ihr auf die Schnelle moderne Singer/Songwriter-Vocals aufnehmen könnt. Wenn ihr möchtet, könnt ihr auch versuchen die maximale Wirkung mit einer völlig rudimentären Instrumentierung zu erzielen. Wir behandeln im Folgenden Gesang und Gitarre, ergänzen diese aber am Ende des Workshops um eine sehr dezente Instrumentierung.
Vorüberlegungen
Wie immer ist es wichtig, sich schon vor der Aufnahme ein klangliches Ziel zu stecken. Wie sollen unsere Vocals klingen? Die Aspekte Authentizität, Feingeist und Sraßenstaub haben wir uns bereits vor Augen geführt; ganz so einfach lassen sie sich natürlich nicht in Klangparameter übersetzen. Aber es ist nicht unmöglich: Um eine gewisse „Echtheit“ zu vermitteln, sollten wir versuchen, die aufgezeichneten Audio-Events der Vocals weder allzu stark zu bearbeiten noch das Vocalsignal mittels exzessiver Signalbearbeitung zu stark zu verbiegen. Klingen die Vocals am Ende dieses Workshops „künstlich“ und vermitteln einen unnatürlichen Eindruck, müssten wir unser kleines Singer/Songwriter-Projekt als gescheitert ansehen. Das Gleiche gilt für den Faktor Feingeist. Wenn in unserem Sing/Songwriter-Stück textliche Nuancen quasi „mit dünnerem Bleistift“ gezeichnet werden als es bei vielen Rock-, Pop- oder Dance-/Club-Stücken der Fall ist, dann darf der Klang unseres Tracks diese feinsinnige Komponente durchaus unterstreichen. Fette, wummernde Bässe und heftiges Kompressorpumpen sind deshalb für die Dauer dieses Workshops für uns ein absolutes No-Go. Stattdessen können wir versuchen, einzelne klangliche Feinheiten von Vocals und Gitarrensound so herauszuarbeiten, dass beide Instrumente für den Zuhörer interessant klingen und sich zugleich klanglich nicht in die Quere kommen. Und damit sind wir auch schon bei der eigentlichen Herausforderung, die uns diese Workshop-Folge stellt: Die Sounds von Gesang und Gitarre sollten in unserem Workshop-Track so ineinandergreifen, dass sie sich ergänzen und nicht bekämpfen.
Wenn wir uns dem Recording und der Produktion eines Sing/Songwriter-Tracks nähern, ist es nicht ganz unerheblich, wie die Stimme des Sängers/der Sängerin beschaffen ist und selbstverständlich auch welche Gitarre zum Einsatz kommt. In unserem Fall haben wir eine volle, tiefe Frauenstimme (Alt) und mit der Cort Earth 100 F eine Low-Budget-Westerngitarre vorliegen. Das Timbre unserer Sängerin ist dabei eher dunkel, enthält aber zugleich eine kehlige Komponente. Hinsichtlich des Ausdrucks enthält die Stimme eine leicht „brüchige“ Note, gerade so, als ob sie im nächsten Moment versagen oder aussetzen könnte. Dadurch kommt ein gewisser Drama-Faktor ins Spiel, den wir unbedingt erhalten sollten. Genau diese Momente sollen uns Authentizität, Feinheiten und gesanglichen „Staub“ liefern. Der Gitarrenklang der Cort Earth 100 F hat dagegen nur eine sehr dezente hölzerne Note und erscheint beim Live-Anspielen des Instruments nicht allzu voll. Die perkussiven, crispen Anteile des Klangs der Stahlsaiten kommen dagegen beim Live-Spiel schön zur Geltung. In Kombination mit unserem eher dunklen Vocal-Timbre haben wir also schon vor der Aufnahme eine gute Kombination, die wir mittels Recording und Bearbeitung zu einer klanglich gut funktionierenden Einheit verbinden können sollten.
Recording
Mikrofonauswahl – Gitarre
Für Mikrofon- und Preampauswahl schauen wir wieder mal einem Top-Producer über die Schulter. Jake Gosling hat nicht nur die Brit-Größe Paloma Faith produziert, sondern sich auch beim Hit-Album „+“ von Ed Sheeran verdient gemacht. Vor allem die Single-Auskopplung „The A-Team“ dürfte Vielen ein Begriff sein. Für die Gitarrenaufnahmen von Ed Sheeran hat Jake Gosling auf zwei SE Electronics 4400a-Mikrofone zurückgegriffen. Und auch wir werden in diesem Workshop eines dieser Mikrofone verwenden.

Optisch erinnert das Mikrofon an den Mikrofonklassiker AKG C414, der als recht neutral klingender Großmembran-Geselle gilt. Das 4400a verfügt über eine Doppelmembran-Großmembran, die zwei 1“-Kapseln beherbergt. Neben Niere und Superniere kann es deshalb auch die Richtcharakteristiken Kugel und Acht bieten. Pad- und LowCut-Funktionen sind ebenso verbaut. Dabei lässt sich das Signal um -10 und -20 dB dämpfen beziehungsweise bei 60 und 120 Hz „abschneiden“. Der Frequenzgang umfasst 20 Hz bis 20 kHz. Das sollte für die Durchführung unserer Gitarrenaufnahmen ebenso reichen wie der maximale Schalldruckpegel von 130 dB, der vom Mikrofon verarbeitet werden kann.
Klanglich ist das SE 4400a ein eher neutraler Geselle. Wenn man von Klangeinflüssen sprechen möchte, muss deshalb stets von Nuancen die Rede sein. Dabei sollte seine äußerst dezente Bassbetonung unserem insgesamt „schwachbrüstigen“ Gitarrensound zu etwas mehr Wärme verhelfen. Ein ähnliches Bild zeigt sich im Bereich der Höhen. Eine wahrnehmbar „schimmernde“ Anhebung ist hier vom 4400a zwar nicht zu erwarten. Doch werden den Höhenanteilen von Signalen, die mit diesem Mikrofon aufgegriffen werden, durchaus „Larger Than Life“-Anstriche nachgesagt. Auf diese Weise verspreche ich mir von seinem Einsatz, dass es dazu beiträgt, den schon angesprochenen „metallenen“ Klanganteil der Saiten herauszuarbeiten, ohne dass für beide Klangaspekte von vornherein ein Equalizer erforderlich wird.
Für die Mikrofonierung der Gitarre kombiniere ich das SE 4400a mit einem Stativ und der mitgelieferten Spinne, in der das Mikrofon von Körper- und Trittschall entkoppelt gelagert wird. Die Signale völlig übersprechungsfrei aufzuzeichnen wird dagegen nicht möglich sein. Dafür sind die Schallquellen einfach zu dicht beieinander. Und ganz ehrlich: Ein Großteil des Charmes von Singer/Songwriter-Aufnahmen entsteht in der Summe gerade durch das lebhafte Ineinandergreifen der verschiedenen Signalanteile. Als Richtcharakteristik habe ich daher die bekannte Niere gewählt.
Das Hochpassfilter des Mikrofons bleibt bei der Gitarrenaufnahme deaktiviert. Eine Signaldämpfung mittels Pad-Funktion ist ebenfalls nicht erforderlich, da unsere Schallquelle nicht übermäßig laut ist. Um die gewünschte „feine Zeichnung“ des Gitarrensounds zu erreichen richte ich das Mikrofon in relativ geringer Entfernung von etwa 15 bis 20 cm auf den Gitarrenhals aus. Dabei setze ich am Übergang von Hals und Übergang an und richte es so aus, dass seine Hauptachse leicht in Richtung der Greifhand zielt. Damit möchte ich erreichen, dass wir neben dem feinen metallisch klingenden „Sirren“ der Stahlsaiten zusätzlich möglichst deutliche Griff- und Rutschgeräusche aufzeichnen. Bei einer Halsmikrofonierung kann der Nahbesprechung durchaus erwünscht sein. Er soll dem Schnarren und Sirren zu einem „wärmeren“ Charakter verhelfen.
Für dich ausgesucht
Mikrofonauswahl – Gesang
Bei den Vocals sieht die Sache ein wenig anders aus. Während Gosling sich für ein SE Electronics Z3300a entschied, um Ed Sheeran’s Gesang aufzuzeichnen, werden wir stattdessen das Modell Z5600a MKII einsetzen, das vom gleichen Hersteller stammt. Wengleich es sich bei beiden Geräten um Großmembran-Kondensatormikrofone mit identischem Frequenzbereich und gleicher Impedanz handelt, sind die Unterschiede dennoch gewaltig. Denn das Z3300a setzt seine Impedanzwandlung mittels FET-Schaltung um, das Z5600a basiert dagegen auf einer Röhrenschaltung. Außerdem verfügt das Z5600a nicht nur über eine größere Empfindlichkeit (14,1 mV/Pa statt 12,6 mV/Pa), sondern auch über ein deutlich geringeres Eigenrauschen (12 dB(A) statt 20 dB(A)) sowie nicht zuletzt über einen um 10 dB höheren Grenzschalldruckpegel (135 dB statt 125 dB). Diese Punkte sollen uns in Verbindung mit dem hoffentlich typischen seidigen Röhrensound dazu verhelfen, unsere Vocals zugleich druckvoll und detailliert aufzeichnen zu können und ihnen zudem eine „rauchige“ Note mit auf den Weg zu geben. So soll zugleich der Stimmcharakter unserer Sängerin eingefangen und schon während des Recordings ein wenig „gepimpt“ werden.

Ich entscheide mich wieder für eine Stativ-Aufstellung des Mikrofons und lagere es in einer Spinne, die Tritt- und Körperschallanteile vermindern soll. Da ich die Stimme nicht allzu nah mikrofoniere, setze ich keinen Popp-Schutz ein und wähle die Richtcharakteristik Hyperniere. Der Bereich, in dem sie Signale aufgreift, ist noch ein wenig enger gefasst als bei einer Nieren-Charakteristik. Dadurch sollen von unserem Vocal-Mikrofon weniger Anteile des Gitarrensignals aufgegriffen werden. Hochpassfilter und Pad-Funktion lasse ich auch hier deaktiviert. Schließlich soll unsere Aufnahme einen möglichst großen Frequenzbereich der Schallquelle Gesang aufgreifen. Denn es ist zwar möglich diesen Frequenzbereich später zu beschneiden, aber kaum, ihn zu erweitern.
Das Mikrofon platziere ich nicht zu nah, da ich ein ausgewogenes Signal erzielen möchte, das nicht zu stark vom Nahbesprechungseffekt geprägt sein soll. Bei einer Ballade sähe das eventuell anders aus. Hier könnte eine sehr nahe Mikrofonierung für einen deutlicheren Nahbesprechungseffekt sorgen, der klangliche „Nähe“ und „Intimität“ ins Spiel bringt. Bei unserem Track handelt es sich aber um einen Song mit Dramacharakter, der die Message „Verzweiflung“ transportiert und weder allzu nachdenklich noch melancholisch daherkommt. Ach, ja: Die Hauptachse des Mikrofons richte ich natürlich auf den Mund der Sängerin aus.
Preamp-Auswahl
Die Wahl der passenden Mikrofone ist natürlich erst die halbe Miete. Es stellt sich noch die Frage, welche Preamps wir für die Verstärkung der aufgegriffenen Signale verwenden sollen. Wer diese Workshop-Reihe kennt, hat schon einige Preamp-Klassiker kennengelernt und weiß bereits, dass so mancher Highend-Vorverstärker auch als Nachbau oder gar als Emulation zu erstehen ist. Das schont den Geldbeutel und bringt dennoch erstklassigen Sound ins Home- und Projektstudio. Doch eins nach dem anderen…
Für die Gitarren-Mikrofone entscheide ich mich ganz unspektakulär für die im Audio-Interface eingebauten Vorverstärker. Der Klang der Preamps im RME Fireface 800 passt meiner Meinung nach gut zum „unaufgeregten“ Gitarrensound, den wir anstreben, und den wir schon mit den SE Electronics 4400a-Mikrofonen auf den Weg gebracht haben.

Weil wir uns in einem Workshop für Vocal-Production befinden, schaue ich für die Vorverstärkung des Vocal-Mikrofonsignals wieder Jake Gosling über die Schulter. Er nutzt in seinem kleinen Studio für Vocal-Produktionen einen Avalon VT-737SP. Dieser Mono-Channelstrip wartet nicht nur mit einem Class-A-Röhrenpreamp auf, sondern bietet auch einen Opto-Kompressor sowie einen diskret aufgebauten 4-Band-Equalizer. Unser Augenmerk gilt an dieser Stelle aber ausschließlich der Preamp-Sektion des Channelstrips. Dynamikbearbeitung und Frequenzeingriffe bewahren wir uns dagegen für später auf. Mit 92 dB fällt das Eigenrauschen des Avalon-Preamps nicht ins Gewicht und sein Headroom ist mit +30 dB großzügig bemessen. Der Klang des VT-737SP gilt gemeinhin als „transparent“, „fein auflösend“ und „edel“. Er eignet sich hervorragend für Mikrofonsignale, die einen etwas „dunkleren“ Charakter haben und wird deshalb gerne mit Mikrofonen wie dem Neumann U67 eingesetzt. Unserer Vocal-Aufnahme kommt das sehr entgegen, da unsere Sängerin ja ein eher „dunkles“ Vocal-Timbre mitbringt. Zusätzlich soll der Röhrenanteil des Preamp-Klangs unseren Vocalsound noch etwas weiter in die „staubige“ und „authentische“ Klangecke manövrieren.
Allerdings steht so mancher Besitzer eines Homerecording oder Projektstudios mit offenem Mund vor der Preamp-Auslage, wenn er den Verkaufspreis des Gerätes liest. Schließlich hat nicht jeder Recordingbegeisterte die Mittel, um sich einen Preamp/Channelstrip für € 2500,- leisten zu können. Es ist kein Geheimnis, dass ich ein Fan der Liquid-Preamps des britischen Herstellers Focusrite bin. Für Vocal-Recordings bieten sie eine riesige Soundauswahl von Preamp-Emulationen, die allesamt hochwertig klingen, und das zu einem erschwinglichen Anschaffungspreis. In dieser Workshop-Folge greife ich nicht auf die Liquid-Preamps des Audiointerfaces Liquid Saffire 56 zurück, sondern verwende den Focusrite Liquid Channel. Er bietet das Preset „Silver 2/US Modern Tube“, hinter dem sich eine Emulation der Klangeinflüsse des Avalon VT-737SP versteckt und mittels „Dynamic Convolution“-Technik erzeugt wird. Zusätzlich passt der Liquid Channel auch die Eingangsimpedanz an die Preamp-Vorlage an. Durch diese Kombination von Faltungsansatz und Änderungen im analogen Signalpfad wird der Sound des VT-737SP erstaunlich gut reproduziert. Für die Aufnahme des Vocalsignals belasse ich das Hochpassfilter wiederum deaktiviert.

Raumauswahl
Die Auswahl einer passenden Recording-Umgebung sieht bei Singer/Songwriter-Aufnahmen natürlich etwas anders aus als bei unseren bisherigen Workshop-Folgen. Ich kann nicht empfehlen, den Künstler mitsamt seiner Gitarre in eine kleine Gesangskabine zu verfrachten, die für einen großen Anteil an frühen Reflexionen sorgt und somit das Abmischen der drei aufgezeichneten Audiosignale deutlich erschweren dürfte. Allein das Aufstellen von zwei Mikrofonstativen zusätzlich zu Künstler/in und Gitarre dürfte in vielen kleineren Kabinen schon Probleme bereiten. Aus diesem Grund habe ich mich dafür entschieden, unser Vocal/Gitarren-Setup im Regieraum meines Projektstudios zu mikrofonieren. Der Raum ist ausreichend groß bemessen und bedämpft, so dass die aufgegriffenen Direktsignale nicht durch Raumhall gestört werden. Und es bleibt genügend Platz, um bequem das Setup aus Sängerin, Gitarre und Mikrofon zu platzieren. Wer keinen ausreichend bedämpften Raum sein Eigen nennt, der kann auch in einen größeren Wohnraum ausweichen, der optimalerweise Sofa, Teppich, Bücherregal, Pflanzen und Vorhänge bietet. Die Raumauswahl soll uns wiederum ein wenig näher an unseren Zielsound bringen. Ein wenig „Lebhaftigkeit“ kommt unserer Produktion dabei zwar zugute, ein unkorrigierbarer, überdeutlicher Raumhall wäre in diesem Fall aber kontraproduktiv. Hören wir uns einmal an, wie die Signale klingen, die ich für euch mit diesem Setup aufgezeichnet habe:
Signalbearbeitung
Das sonst bei Rock- und Pop-Produktionen typischerweise durchgeführte Voal-Editing lasse ich in diesem Fall vollständig aus. Tonhöhenkorrekturen und rhythmische Ausbesserungen haben an dieser Stelle nicht nur stilistisch nichts verloren, sondern sind vor allem aufgrund der starken Übersprechungen der aufgezeichneten Signale mit äußerster Vorsicht zu genießen. Um die Authentizität der Performance nicht in Mitleidenschaft zu ziehen, beschränken wir uns stattdessen ausschließlich auf Dynamik- und Frequenzbearbeitung und werden anschließend noch Räumlichkeit und Stereobreite ins Visier nehmen.

Dynamik- und Frequenzbearbeitung Vocals
Sowohl Vocals als auch Akustikgitarre habe ich als Mono-Spur aufgezeichnet. Dabei kommt es aufgrund von Laufzeitunterschieden der Signalquellen in Bezug auf die Mikrofonpositionen zwischen den Signalen von Vocals und Akustikgitarre zu einem deutlich hörbaren Kammfiltereffekt, der den natürlichen Klangcharakter der Vocals stört. Um ihm entgegenzuwirken, setze ich im Insertweg des Akustikgitarrenkanals das Steinberg MonoDelay mit einem Wet-Wert von 100% ein. Mit seiner Hilfe verzögere ich das Signal um 1 ms. Das Ergebnis ist ein vollerer Klang nebst ein wenig Pegelgewinn, da Wellentäler und -berge der beiden Audiosignale nun deutlich synchroner sind. Selbstverständlich ließe sich der gleiche Effekt auch durch das Verschieben des Audioevents auf der Akustikgitarrenspur um 1 ms erzielen.


Um das Signal der Vocals ein wenig zu verdichten, setze ich einen LA-2A-Kompressor von UAD ein. Mit seiner Hilfe komprimiere ich die Signaldynamik um nicht wesentlich mehr als 2 dB. Es geht nicht darum, die Vocals laut zu machen, sondern lediglich ihre Dynamik etwas ausgeglichener zu gestalten. Das war es auch schon in Sachen Dynamikbearbeitung der Vocals.


Um das Frequenzbild des Vocalsignals für das Zusammenspiel mit anderen Instrumenten zu optimieren, setze ich einen Neve 1073-EQ von UAD ein. Hier gibt es das Preset „VOX-Female Vocal Warmth“, das unseren Vocals auf Anhieb auf die Sprünge hilft. Nicht nur, dass ein Low-Cut-Filter den Frequenzbereich unterhalb von 90 Hz freischaufelt: Zusätzlich werden auch die Mitten bei 4,8 kHz leicht abgesenkt, wodurch die Vocals etwas an Kehligkeit verlieren. Als Nächstes verringere ich die Zischlaute unseres Vocalsignals mithilfe des Steinberg DeEsser-Plug-Ins. Hier passen die Standardeinstellungen des DeEssers bereits perfekt zu unserem Vocalsignal und sorgen für eine Pegelabsenkung von [s]- und [sch]-Lauten um bis zu über -8 dBFS.
Dynamik- und Frequenzbearbeitung Akustikgitarre
Nun widmen wir uns einer ausgeglicheneren Dynamik des Akustikgitarrensignals. Hier greife ich auf eine sanfte Kompression des von UAD stammenden LA-3A Audio Levelers zurück. Er sorgt in unserem Workshop-Track für eine maximale Stauchung der Signaldynamik von etwa 1 dBFS und gestaltet damit die Dynamik des Akustikgitarrensignals geringfügig kohärenter.

Auch bei der Akustikgitarre setze ich wieder die Plug-In-Emulation des Neve 1073-EQs von UAD ein. Dadurch sollen beide Signale – Vocals und Gitarre – einen ähnlichen Grundcharakter erhalten, der jedoch frequenztechnisch ineinandergreift. Ich entscheide mich auch bei der Akustikgitarre wieder für ein Preset, und zwar „INST-Acoustic Gtr Rhythm“. Es senkt ebenfalls die Frequenzen unterhalb 90 Hz ab und verringert zusätzlich Signalanteile, die um 110 Hz herum liegen. Dadurch wirkt das Gitarrensignal deutlich weniger muffig. Um 7,8 kHz herum findet dagegen eine verhältnismäßig starke Anhebung statt. Dadurch gewinnt die Akustikgitarre an Durchsetzungskraft und auch Spielgeräusche werden besser hörbar. Und auch die Zischlaute der Vocal-Anteile im Akustikgitarrensignal müssen wir noch verringern. Wiederum greife ich auf das Steinberg DeEsser-Plug-In mit Standardeinstellungen zurück, die hier eine Pegelabsenkung der [s]- und [sch]-Laute um bis zu über -9 dBFS bewirken.
Wenn ich mir das Zusammenspiel von Vocal- und Akustikgitarrensignal anhöre, stelle ich fest, dass hier leveltechnisch nachgebessert werden kann. Ich fahre deshalb den Fader des Akustikgitarrenkanals auf -15 dBFS herunter. Daraufhin werde ich dem Monosignal der Akustikgitarre ein wenig Stereobreite verleihen, da sie für meinen Geschmack etwas zu eindimensional wirken. Dazu lege ich einen Stereo-Gruppenkanal an, in den ich das Ausgangssignal des Akustikgitarrenkanals hineinroute und benenne den Gruppenkanal mit „GIT2Stereo“. Im Insertweg des neu angelegten Stereo-Gruppenkanals öffne ich das Steinberg-Plug-In Mono2Stereo mit dessen Hilfe ich für deutlich mehr Stereobreite des Akustikgitarrensignals sorge. Aufgrund der Fader-Pegelabsenkung des Akustikgitarrensignals um 15 dBFS wirkt die verhältnismäßig starke Stereobreite dennoch nicht zu aufdringlich.
Räumlichkeit und Stereobreite Dem Vocalsignal fehlt es für meinen Geschmack an Räumlichkeit, deshalb setze ich im ersten post Fader gelegenen Insert-Slot des Vocal-Kanals die Plattenhall-Emulation des UAD EMT140 ein. Selbstverständlich könnt ihr hier auch ein von euch favorisiertes Plate Reverb verwenden. Ich selbst schätze jedoch den weichen Klangcharakter des EMT140. Das „Polished Plate“-Preset gibt uns die Grundeinstellungen eines blitzsauberen Plattenhalls an die Hand, bei dem ich lediglich das Dry/Wet-Verhältnis nachregle. Das Resultat ist ein nicht zu aufdringlicher Hall auf unseren Vocals, der diese dennoch ausreichend mit „räumlicher“ Tiefe ausstattet und in meinen Ohren die emotionale Komponente der Vocal-Performance schön unterstützt.


Final Touch
Für den Gesamtmix habe ich unseren Workshop-Track mit EZdrummer noch um Nashville-Drums angereichert und mittels EZkeys ein paar Einwürfe eines Upright Piano ergänzt. Für das Bass-Fundament sorgt der Tube Drive Finger Bass aus Steinbergs HALion Sonic SE. Zusätzlich liefern die EZmix-Presets „Bigger Drums“, „Moody Piano“ und „SubStantial“ schnelle Mixergebnisse, damit wir auf Anhieb hören, wie unsere Vocal- und Gitarrenbearbeitungen im Mix funktionieren. Dabei fällt mir auf, dass die Dynamik der Vocals trotz geringer Kompression immer noch durchweg zu flatterhaft klingt.
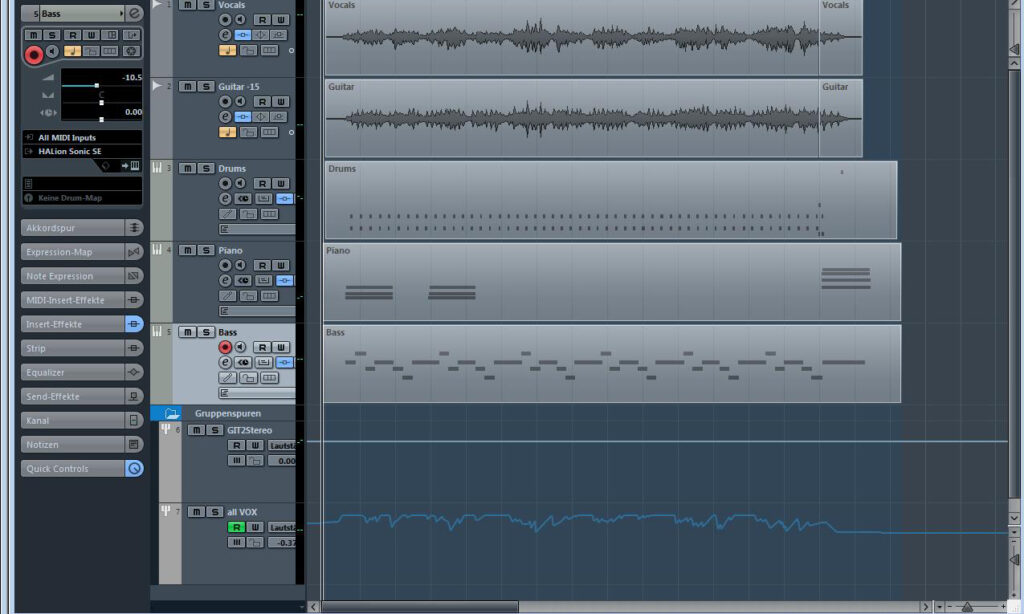
Aus diesem Grund habe ich mich entschieden, einen weiteren Stereo-Gruppenkanal anzulegen, in den ich sowohl das Signal des Vocal-Kanals als auch das des Stereogruppenkanals „GIT2Stereo“ einspeise. Da der neue Stereogruppenkanal nun alle Signale mit Vocal-Beteiligung zusammenführt, bennene ich ihn mit „all VOX“. Jetzt sorge ich in aufwändiger Feinarbeit für eine Lauststärke-Automation, indem ich in der betreffenden Automationsspur des Kanals „all VOX“ Automationspunkte einzeichne. Ziel ist es dabei, einerseits solche Vocal-Details herauszuarbeiten, die sonst kaum hörbar sind (etwa Atemgeräusche, Abschlusskonsonsanten usw.). Andererseits soll die Lautstärke solcher Vocal-Stellen verringert werden, die allzu prominent klingen, jedoch keine wesentlich neue musikalische Information beisteuern. Wem es etwas einfacher reicht und wer nur eine gleichmäßigere Lautstärke erzielen möchte, darf hier durchaus auch Plug-Ins wie den Waves Vocal Rider einsetzen. Das Ergebnis kann überzeugen: Wie der Hörvergleich mit der nicht-automatisierten Variante dieser Signalkombination zeigt, wirkt die Lautstärkeverteilung des Gesangs-/Gitarrensignals nun deutlich ausgewogener, Details kommen besser zur Geltung, störend prominente Stellen sind jetzt wesentlich defensiver.
Wie in jeder Workshopfolge, so habe ich auch dieses Mal wieder den fertigen Track mit iZotope Ozone 5 gemastert. Da die gemasterte Version deutlich lauter ist als die Mix-Tracks, solltet ihr daran denken, vor dem Anhören der Abschluss-Tracks die Lautstärke eurer Monitore/Kopfhörer herunterzuregeln. Zunächst hört ihr eine gemasterte Variante mit „trockenen“ Vocal- und Akustikgitarren-Signalen. Dann könnt ihr euch abschließend den gemasterten Workshop-Track inklusive aller vorgestellten Eingriffe anhören.
Zu guter Letzt
Wir wollten mit einem möglichst einfachen Setup eine authentischen Singer/Songwriter-Sound einfangen, dessen Emotionalität nicht durch technischen Schnickschnack gestört werden sollte. Aus diesem Grund habe ich in diesem Workshop auf Pitch-Shifting, auf Zeitkorrekturen sowie auch auf Comping verzichtet. Wir haben ausschließlich ein First Take verwendet, das nur einen einzigen Schnitt am Ende enthält, um unsere Aufnahme auf Workshop-Länge zu kürzen. Eine dezente Dynamikbearbeitung erhält die Lebendigkeit des Materials, kleinere EQ-Eingriffe sorgen hauptsächlich für sanfte Signalausgestaltungen, statt die Audiosignale zu „verbiegen“. Um die musikalische Performance zu unterstützen, aber nicht von ihr abzulenken, wurden sowohl Hall als auch Stereoverbreiterung vergleichsweise dezent eingesetzt. Insgesamt kann deshalb unsere Mission als erfolgreich betrachtet werden.
Dennoch schließe ich auch in diesem Workshop mit Antworten auf die Frage „Was hätte man besser machen können?“. Selbstverständlich hätten die festgestellten Kammfiltereffekte bereits während der Aufnahme verhindert werden können. Möglich wäre hier eine bessere Platzierung der Mikrofone oder auch eine getrennte Aufnahme beider Signalquellen gewesen. Ähnliches gilt für die Stereobreite. Anstelle zweier Monosignale wäre es im Sinne eines authentisch klingenden Audiosignals förderlich gewesen, die Akustikgitarre mit einem Stereo-Mikrofonierungsverfahren aufzuzeichnen statt das vorhandene Monosignal nachträglich künstlich zu verbreitern. Im Bereich der räumlichen Tiefe ist es wie immer Geschmackssache, wieviel Hall im Mix verwendet wird. Mit etwas Abstand angehört hätte es für meinen Geschmack ruhig etwas weniger Plattenhall sein dürfen, um kein zu starkes 80s-Feeling zu erzeugen.
Ich hoffe, der Workshop hilft euch dabei, fantastisch klingende Singer/Songwriter-Recordings zu erstellen und abzumischen. Viel Spaß dabei!
Vocals: Julia Scheibeck



























