
Keine Frage: Bigroom House mit French Touch ist in den letzten Jahren schwer angesagt gewesen. Gerade der Gesang spielt hier eine tragende Rolle. Wie man House-Vocals produziert, zeigen wir euch in dieser Folge unseres Vocal-Production Workshops am Beispiel eines typischen Guetta-Hits. Für “Titanium” holte sich der umtriebige Franzose Unterstützung von der australischen Sängerin Sia Unterstützung.

Mein Kollege Lasse Eilers hat sich in der Produce-Alike-Reihe schon mit der Beat-Produktion von Titanium auseinandergesetzt, damit ihr diesen Track nachbauen könnt! In diesem Workshop kümmern wir uns um das Recording, die Bearbeitung und den Mix der Lead-Vocals.
Vorüberlegungen
“Titanium” besticht durch einen insgesamt sehr “aufgeräumten” Sound. Die verwendeten Instrumente übernehmen recht eindeutige Funktionen und bekommen auch mixtechnisch einen klaren Platz zugewiesen, der dann für das jeweilige Instrument reserviert wird (bspw. im Frequenzbild). Daraus ergibt sich ein sehr vielschichtiger und kompakter Gesamtsound, bei dem die einzelnen Signale rhythmisch und frequenzmäßig gut ineinander greifen. Das gilt auch für die Vocals. Unsere Aufgabe wird es deshalb sein, ein sehr sauberes Gesangssignal aufzuzeichnen, das wir so weiterbearbeiten, dass es einen deutlich abgegrenzten Frequenzbereich besitzt, zugleich aber nicht allzu steril klingt. Denn der Guetta-Track lebt auch davon, dass die Vocals von Sia einen stark emotionalen Charakter haben. Diesen wollen wir ebenfalls aufzeichnen und bis in den Mix weitertransportieren. Entgegen den vorangegangenen Workshops werden wir diesmal darauf achten, dass die Vocals recht weit im Vordergrund stehen. Denn charttaugliche Musik funktioniert heute genau so: Die Lead-Vocals dienen dem Zuhörer als Anker für seine Aufmerksamkeit, alle weiteren Instrumente unterstützen die Vocals bei dieser Aufgabe oder sorgen für Groove und Atmosphäre. All diese Punkte werden wir beim Bearbeiten und Mischen der Lead-Vocals bedenken müssen.
Recording




Mikrofonauswahl
Als erstes machen wir uns Gedanken über die Auswahl des Mikrofons. Auf der Suche nach einem Mikrofon, dass in der Lage ist einen einigermaßen “warmen” Sound zu liefern, ohne dabei gleich “muffig” zu klingen, bin ich über das Golden Age Project TC-1 gestolpert. Golden Age Project machen seit einiger Zeit durch preiswerte Geräte auf sich aufmerksam, die in die Highend-Richtung “schielen” – wie etwa Mikrofon-Preamps im Stil des legendären Neve 1073 (bonedo-Tests mkII und DLX). Zum Produkt-Portfolio der Schweden zählen auch Mikrofone verschiedenster Bauarten. Das TC-1 ist dabei eines der Top-Produkte. Es handelt sich um ein Großmembran-Röhrenmikrofon mit Hochpassfilter und Pad-Schaltung, das der Hersteller mit dem Hinweis bewirbt, dass es ebenso “warm” klingt wie einige weit verbreitete Mikrofonklassiker.
Zum Produkt-Portfolio der Schweden zählen auch Mikrofone verschiedenster Bauarten. Das TC-1 ist dabei eines der Top-Produkte. Es handelt sich um ein Großmembran-Röhrenmikrofon mit Hochpassfilter und Pad-Schaltung, das der Hersteller mit dem Hinweis bewirbt, dass es ebenso “warm” klingt wie einige weit verbreitete Mikrofonklassiker.
![Abbildung: Golden Age Project TC-1 [Quelle: www.goldenagemusic.se]](https://storage.googleapis.com/th-bonedo-images/wp-media-folder-bonedo//var/www/html/web/app/uploads/2013/09/GAP_TC1-1024x614.jpg)
Einen tatsächlichen Vintage-Sound des Mikrofons kann ich dem Mikrofon allerdings nicht unbedingt zwar nicht unbedingt attestieren. Doch halte ich das TC-1 für ein gutes preisgünstiges Mikrofon, dass durchaus in der Lage ist, Gesangsstimmen schlichtweg ein wenig “runder” und “weicher” klingen zu lassen. Ob diese Qualität ausreicht, um einen Mikrofonklang als “vintage” zu bezeichnen, bleibt sicher jedem selbst überlassen. Das in China gefertigte Mikrofon arbeitet mit einer goldbeschichteten 26mm-Membran, für den Röhrencharakter ist eine 12AT7-Röhre verbaut. Diese steht in dem Ruf, im Gegensatz etwa zu einer 12AX7-Röhre aufgrund ihrer geringeren Ausgangsleistung krasse Transienten abzuschwächen. Die Röhrenschaltung ist in diskreter Class A-Technik gehalten, ein Ausgangsübertrager sorgt für die Signalsymmetrierung. Als Richtcharakteristiken können neben Nieren-, Kugel- und Achtercharakteristik auch sechs weitere Zwischenformen gewählt werden. Außerdem finden sich hier Schalter zum Aktivieren des Hochpassfilters und der Pad-Funktion. Der Frequenzumfang von 20 Hz bis 20 kHz ist für unsere Zwecke optimal und die Empfindlichkeit von 15 mV/Pa ist für die von uns geplante Aufnahme (Close Recording) vollkommen ausreichend. Das Eigenrauschen des Mikrofons liegt mit
Preamp-Auswahl
Weiter geht’s mit der Wahl des Preamps. Schon in einigen der letzten Folgen haben wir das ein oder andere virtuelle Vorverstärker-Modell des Liquid Preamps aus dem Focusrite Liquid Saffire 56 eingesetzt. Das ist auch in diesem Workshop wieder der Fall. Mit dem TC-1 haben wir zwar ein Mikrofon gewählt, dass den Klang etwas “runder” gestaltet. Damit haben wir der “Weichheit” des Signals aber auch schon ausreichend auf die Beine geholfen. Mit der Wahl des Preamp-Modells wollen wir dagegen klanglich für Klarheit und einen modernen Charakter sorgen. Ich entscheide mich deshalb für das Liquid Preamp-Preset “NewAge1”. Dahinter verbirgt sich die Liquid-Version eines Millennia HV-3D.


Das Original ist ein Highend-Gerät, dessen UVP von knapp € 3500,- das Budget der meisten Heimstudios deutlich übersteigen dürfte. Der vollständig in Class A-Technik gefertigte Millennia-Preamp ist für seinen immensen Headroom bekannt. Und was man ihm definitiv nicht nachsagen kann, ist die typische transformerbasierte Klangfärbung, wie sie von anderen Preamps bekannt ist. Das ist kein Wunder, ist der HV-3D doch übertragerlos aufgebaut. Damit sollten wir auf der Suche nach einem puristischen Vorverstärker, der unser Mikrofonsignal “exakt”, schnörkellos und detailliert verstärkt, fündig geworden sein.
Am Liquid Saffire 56 belasse ich den “Harmonics”-Regler der Preamp-Emulation in seiner Grundstellung (auf “7”) und pegle das Signal hoch genug ein, dass der Signal-Rausch-Abstand gut ist, jedoch garantiert keine Verzerrungen auftreten werden (in unserem Fall Gain-Regler auf ca. “+6,5”).
Raumauswahl
Eine kurze Überlegung ist natürlich auch in diesem Workshop wieder der Aufnahmeraum wert. Allerdings fallen die Anforderungen diesmal deutlich geringer aus. Denn die Raumbeschaffenheit ist für unsere geplante Aufnahme (nahezu) unerheblich, sofern nicht zu viele Reflexionen (vor allem frühe) mit aufgezeichnet werden. Grund dafür ist die Entscheidung, die Stimme unserer Sängerin per Close Miking aufzunehmen. Das heißt, sie befindet sich mit ihrem Mund nur etwa 10 cm vor der Mikrofon-Membran entfernt. Dadurch entsteht im Zusammenspiel mit der gewählten Nierencharakteristik des Mikrofons ein deutlicher Nahbesprechungseffekt, den wir nutzen wollen, um die eher hohen und wenn man so möchte “dünnen” Vocals unserer Vokalistin etwas voller klingen zu lassen.
Eine nahe Mikrofonierung birgt jedoch auch Gefahren. So können beispielsweise Zischlaute, Reibelaute, Popplaute und Atmungsgeräusche durch unerwünschte “unmusikaliche” Signalanteile deutlich zu laut ausfallen oder sogar dafür sorgen, dass ein Take unbrauchbar wird. Aus diesem Grund lagern wir das Mikrofon nicht nur zum Schutz vor Tritt- und Körperschall in seiner mitgelieferten Spinne, sondern verwenden zusätzlich auch einen Popp-Schutz. Er sorgt dafür, dass Luft, die auf direktem Weg zur Mikrofon-Membran strömt, diffundiert wird – also gewissermaßen “zerströmt”.
Hören wir uns einmal an, wie unsere Lead-Vocals mit dem TC-1 und dem virtuellen Millennia-Preamp klingen:
Editing
Comping
Für die Lead-Vocals habe ich insgesamt zehn Takes aufgezeichnet, aus denen ich nun die besten Stellen heraussuche. Hierbei hilft mir die Comping-Funktion in Cubase. Durch einen Klick auf den “Takes”-Button der Lead-Vocals-Spur werden mir deren Unterspuren angezeigt. Ich markiere alle Unterspuren und kann so Schnitte für alle Unterspuren gleichzeitig ausführen. Wichtig dabei ist, dass die Raster-Funktion deaktiviert ist. Denn anstatt takt- oder schlagweise zu schneiden, zerschneide ich die Unterspuren des Vocal-Tracks in sprachliche Sinneinheiten. Das können einzelne musikalische Phrasen, einzelne Wörter oder auch einzelne Silben sein. Was auf den ersten Blick sehr aufwändig erscheint, ist in der Praxis definitiv die Mühe wert. Um den Überblick zu behalten, suche ich mir zunächst das Take mit der besten Performance heraus und kennzeichne es (bspw. durch grüne Farbgebung). Nun aktiviere ich die Raster-Funktion wieder und setze einen Loop, der die erste zusammenhängende Phrase der Vocal-Recordings wiedergibt. Dann höre ich mir für das erste der herausgeschnittenen Events nach und nach alle verfügbaren Alternativen der anderen Unterspuren an und lasse letztlich dasjenige Event aktiv, dass der gewünschten Performance am nächsten kommt. Entscheidend ist, auch auf die Klangfarbe der Stimme, kleine Timingunterschiede und Knackser im Übergang zwischen den Parts der verschiedenen Unterspuren zu achten. Ist ein zusammenhängender Songteil bearbeitet und tritt ein Knackser an der Schnittstelle auf, sollten die verwendeten Events markiert und per Crossfade ineinander gefadet werden (in Cubase bspw. per [Strg]+[X]). Diese Schritte wiederhole ich für den gesamten Song beziehungsweise unser gesamtes Song-Snippet. Das fertige “Best Of” aus allen zehn Recording-Takes klingt nach diesem Bearbeitungsschritt so:
Pitch
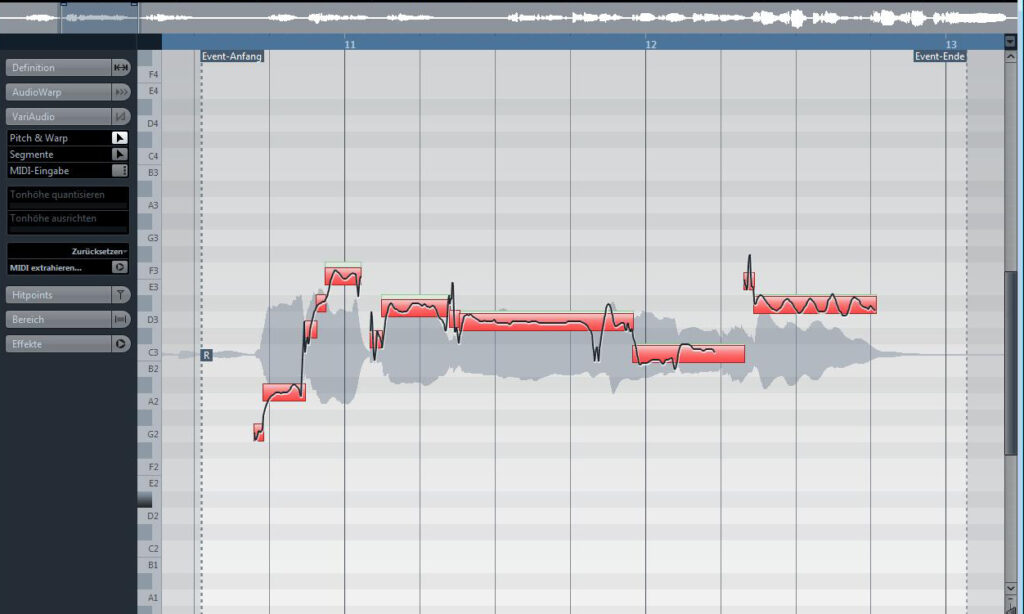
Während wir in den letzten beiden Vocal Production-Workshops darauf Wert gelegt haben, nur in sehr geringem Maße Tonhöhenkorrekturen einzusetzen, können sich Freunde von Melodyne, VariAudio und ähnlichen Software-Tools dieses Mal auf eine exzessive Bearbeitung freuen. Das “harte” Pitchen der Tonhöhen ist zum einen möglich, da unser Track einen sehr “dichten” Sound hat. Zum anderen gibt es das technisch orientierte Musikgenre House Music einfach her, die Stimme der Sängerin ein bisschen weniger “natürlich” klingen zu lassen als in Stilen wie Blues oder Jazz.
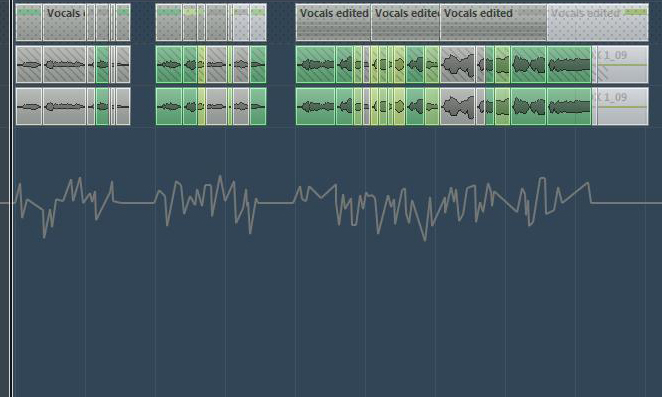
Dennoch sollten wir auch in diesem Fall nicht soweit gehen, die Tonhöhenkorrektur als eigenständigen Effekt einzusetzen. Ziel der Bearbeitung soll sein, die Vocals als Instrument zu stärken, indem wir ihnen eine messerscharfe Intonation spendieren. Das wird umso wichtiger sein, wenn wir im “Vocal Glamour”-Workshop sechs weitere Stimmen hinzuaddieren werden, die für die Mehrstimmigkeit sorgen. Schließlich ist ein Akkord immer nur so stark, wie sein schwächster Ton… Um diese bestmögliche Intonation zu erreichen, quantisiere ich nicht nur einzelne gehaltene Töne mit der VariAudio-Funktion von Cubase. Vielmehr setze ich hier und da einen Schnitt zwischen Toneinsatz und gehaltenem Ton. Denn der Toneinsatz kann in der Intonation häufig noch ein wenig schwankend sein – wenn man so will “sucht” der Sänger/die Sängerin hier noch die richtige Tonhöhe. Dann greife ich den Start-Handler des gehaltenen Tons und verschiebe ihn in Richtung des Toneinsatzes. Der Toneinsatz wird dadurch ein wenig kürzer und es wirkt, als ob der Sänger/die Sängerin den gewünschten Ton schneller findet. Bei Recordings von ungeübteren Sängern kann auch der Tonabsatz nach demselben Muster bearbeitet werden: Tonabsatz vom gehalten Ton abschneiden und den End-Handler des gehaltenen Tons in Richtung Tonabsatz verschieben, um so dessen Länge zu verkürzen. Die eigentliche Tonhöhenkorrektur behalte ich mir dann für den gehaltenen Ton vor. So klingen auch heftige Tonhöhenkorrekturen der gehaltenen Töne in der Regel noch weitgehend natürlich. Mit diesem kleinen Editing-Trick lassen sich erstaunliche Ergebnisse erzielen. Schon mit wenigen Schnitten klingt der Gesang mit dieser Bearbeitungsmethode deutlich professioneller und die Vocals erstrahlen in bestem Scheinwerferlicht.
Im Screenshot ist diese Taktik an fünf Stellen sehr gut zu sehen. Den (geringfügigen) Unterschied, den die Tonhöhen-Quantisierung ausmacht, könnt ihr im Screenshot im Vergleich zwischen grünen und pinkfarbenen Events-Balken erkennen. Und so klingen unsere editierten Lead-Vocals:
Mix
Frequenzbild
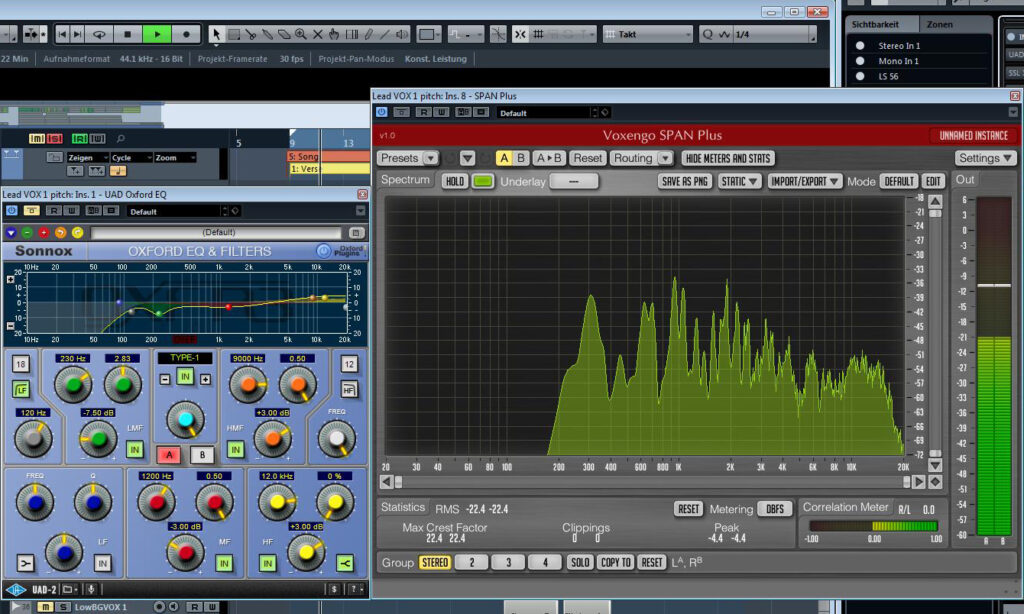
Wir erinnern uns: Unser Ziel ist es, unseren Vocals nach Möglichkeit innerhalb eines klar umrissenen Frequenzbereichs auftreten zu lassen. Deshalb setze ich im ersten Mix-Schritt einen Equalizer im Insertslot des Lead Vocal-Kanals ein. Denn unsere noch etwas “muffig” klingenden Vocals benötigen deutlich mehr Brillanz, um sich im Mix unter anderem gegen die höhenlastigen Synthesizersounds durchsetzen zu können. Als Equalizer wähle ich den Sonnox Oxford EQ von UAD. Er bietet mit insgesamt sieben Bändern eine enorme Auswahl an Eingriffsmöglichkeiten und gehört zu den eher “chirurgischen” Vertretern unter den Software-Equalizern. Deshalb haben wir jenseits der EQ-Einstellungen keine Signalfärbung zu erwarten, was unserem ausgeschriebenen Klangziel entgegenkommt.
Per Low-Cut-Filter blende ich Frequenzen unterhalb von 120 Hz aus. Dabei wähle ich eine mittlere Filter-Slope von 18 dB/Oktave, wodurch ich ein krasseres Ergebnis erhalte, als es das Hochpassfilter des Mikrofons hätte leisten können. Außerdem senke ich die Frequenzanteile im Bereich um 230 Hz gezielt ab (hohe Filtergüte von 2,8), um den Vocals etwas an “Kistigkeit” zu nehmen. Die leicht herausstechenden Stimmformanten senke ich mit einem weiträumigen EQ (geringe Filtergüte von 0,5) rings um die Center-Frequenz 1,2 kHz um 3 dB ab. Das dient vor allem dazu, den darüber liegenden Höhenanteil zu betonen, ohne diesen boosten zu müssen. Beim Abhören stelle ich fest, dass die Bearbeitung leider immer noch nicht ausreicht, um ein detailliert-brillantes Signal zu erzielen. Dafür sorge ich mit einer abschließenden Anhebung bei 9 und bei 12 kHz um je 3 dB mittels eines Glockenkurven- und eines nachgeschalteten Kuhschwanzfilters. Wie der Screenshot der Frequenzanalyse zeigt, kann sich das Ergebnis sehen (und vor allem auch hören) lassen. Der Frequenzbereich unserer Vocals ist nun klar abgesteckt, wirkt insgesamt ausgeglichener und enthält eine gehörige Portion Höhen. Genau so soll es für unseren House-Track sein.
Signaldynamik
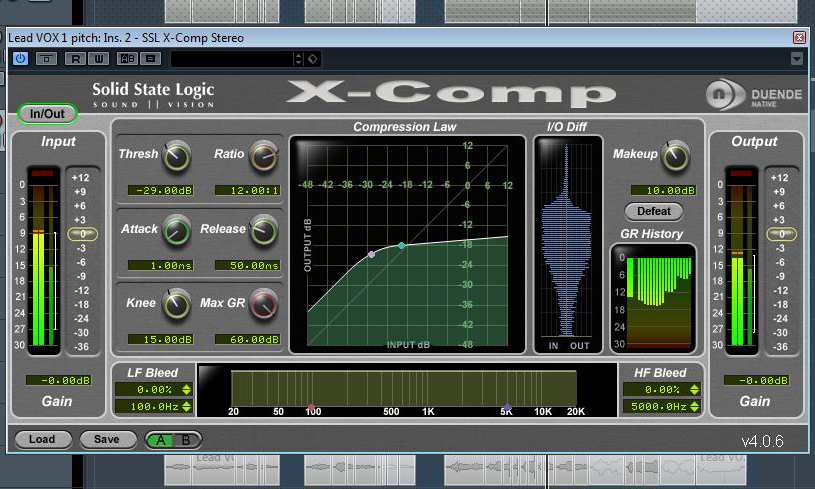
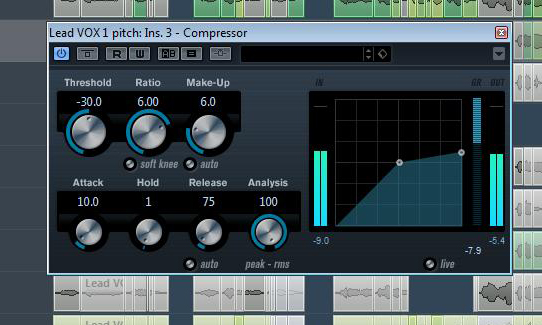
Noch ist die Dynamik unserer Vocals zu unausgewogen, als dass sie ohne Weiteres im dichten House-Sound des Mixes platziert werden könnten. Um die Vocal-Dynamik einzugrenzen, greife ich auf die bewährte Technik der doppelten Kompression zurück. Zunächst fange ich mit kurzen Attack und Releasezeiten die heftigsten Signalspitzen des Gesangs ein. Hierzu verwende ich im Insertslot des Lead-Vocal-Kanals das Plug-In X-Comp aus dem Duende Native-Bundle von SSL. An ihm gefallen mir vor allem seine Analyse-Tools. Sie sorgen für einen optimalen Überblick über die Dynamikveränderungen, die die eingestellte Kompression beim Signal bewirkt. Mit einem radikalen Kompressionsverhältnis von 12:1 sorge ich dafür, dass die Signalspitzen auf bis zu -18 dBFS zurückgefahren werden. Im Screenshot ist dieser radikale Eingriff im Plug-In-Bereich “GR History” zu sehen. Ich habe mich dabei bewusst für einen niedrigen Schwellenwert entschieden. Dadurch werden letztlich nicht nur die Signalspitzen, sondern auch ein Großteil des “Bodies” der Vocal-Dynamik komprimiert. Wie im Audiobeispiel zu hören, klingen unsere Lead-Vocals dadurch schon ein ganzes Stück zahmer.
Im zweiten Kompressionsschritt sorgen wir dafür, dass nicht nur die Signalspitzen, sondern die gesamte Signaldynamik eingeebnet wird. Dafür setze ich im Insertslot des Lead Vocal-Kanals den Kompressor aus den Cubase-Bordmitteln ein. Etwaiges “Pumpen”, das durch die Doppel-Kompression entsteht, soll uns hier nicht weiter stören, so lange es “musikalisch” wirkt. Schließlich haben wir einen House-Track vor der Brust, der auch sonst kaum authentische Instrumenten-Dynamik, sondern eher “das volle Brett” liefert. Attack- und Releasezeiten wähle ich deutlich länger als im ersten Kompressionsschritt. So erfolgt die Kompression in diesem Schritt deutlich träger als noch im ersten. Mit einem für diesen Zweck relativ hohen Komprimierungsverhältnis von 6:1 sorge ich für eine stark eingeschränkte Signaldynamik. Das Ergebnis klingt deshalb hinsichtlich der Dynamik grundverschieden zum vorangehenden Bearbeitungschritt:
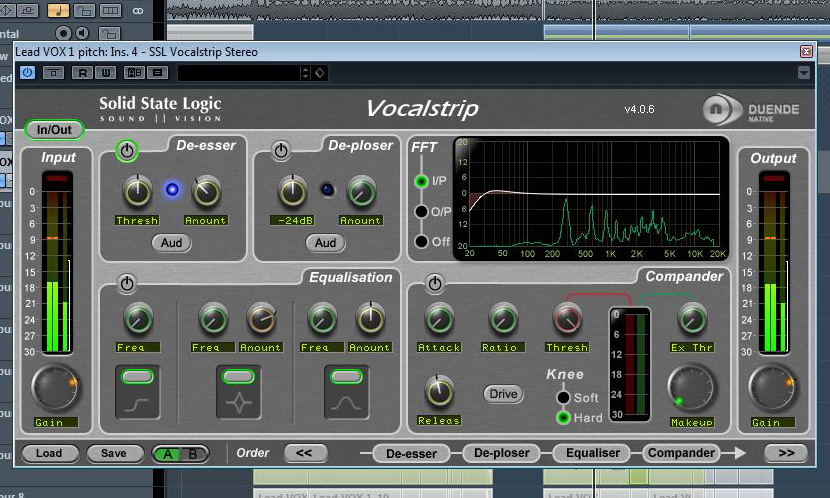
Ein kleines Problem stellen nun allerdings die Zisch- und Reibelaute der Vocals dar. Sie kommen durch die Doppel-Kompression allzu deutlich heraus. Deshalb setze ich im nächsten Insertslot ein weiteres SSL-Plug-In ein. Wie der Name “Vocalstrip” nahe legt, ist dieses Tool auf die Bearbeitung von Gesangssignalen spezialisiert. Aus meiner Sicht enthält es einen der leistungsstärksten De-Esser, die in der Plug-In-Welt zu finden sind. Mit der Hilfe von nur zwei Reglern lässt sich nahezu jedes Problem mit “S”- und “Sch”-Lauten lösen. Besonders hilfreich ist dabei die Audition-Schaltung, bei deren Aktivierung ausschließlich derjenige Signalanteil wiedergegeben wird, der der Arbeit des De-Essers zum Opfer fällt. Oftmals reicht es beim Vocalstrip aus, das Maß des De-Essers auf 25-33% einzuregeln. So auch in diesem Fall. Das Ergebnis klingt deutlich weicher und wiederum ausgewogener als noch im Schritt zuvor.
Klangliche Breite und Sättigung
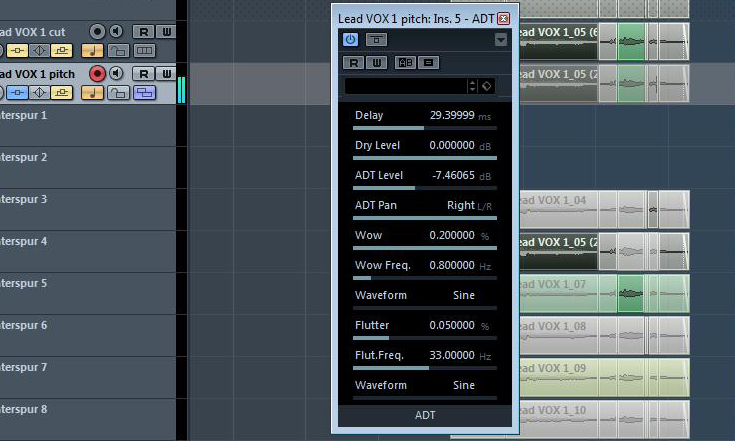
Was dem Gesangssignal definitiv noch fehlt ist der “Larger Than Life”-Charakter, der so viele Vocals aktueller Pop-Produktionen auszeichnet. Das gilt für House-Musik in besonderem Maße. Zur “Verbreiterung” des Signals setze ich deshalb im nächsten Insert-Slot das Freeware-Plug-In ADT von Vacuumsound ein. “ADT” steht für “Artificial Double Tracking” – auf Deutsch “künstliche Spur-Dopplung”. Das Plug-In sorgt dafür, dass das Originalsignal zu einer Seite des Stereobilds ausgelenkt wird und eine verzögerte Kopie auf der anderen Stereoseite addiert wird. Dieses Signal wird durch verschiedene Effekte wie Wow und Flutter weiterbearbeitet. Diese imitieren Klangveränderungen, die durch Gleichlaufschwankungen von Tonbandmaschinen entstehen. Das Resultat ist ein deutlich “breiterer” Sound. Für unsere Vocals reicht dabei schon ein geringer ADT-Anteil aus, den ich mit etwa -7,5 dB zum 0 dB-Originalsignal hinzu gebe.
Was dem Signal nun noch fehlt, ist ein Hauch mehr “Leben”. Dieses versuchen wir nun mittels einer leichten analogen Sättigung zu gewinnen. Das Plug-In iZotope Nectar ist ebenfalls ein spezielles Vocal-Tool. Es enthält unter anderem einen “Saturation”-Bereich, in dem unsere Vocals um eine geringe 25%-ige analoge Sättigung ergänzen. Den “Mix”-Regler setze ich dabei auf “100%”, damit ausschließlich das bearbeitete, gesättigte Signal das Plug-In verlässt. Zusätzlich setze ich den nachfolgenden Limiter des iZotope Nectar als Brickwall ein. Der Klangunterschied ist subtil, aber nichtsdestotrotz wirkungsvoll.


Räumlichkeit und Lautstärke-Automation
Der Grundsound unserer Lead-Vocals steht, nun können wir uns der Anpassung der Lautstärke und der Räumlichkeit widmen. Per Automation der Lautstärke des Lead Vocal-Kanals versuche ich zu erreichen, dass die Vocals besser im Mix “sitzen”. Das heißt, dass leise Stellen deutlicher hervorkommen (wenn gewünscht) und der Pegel allzu lauter Stellen zurückgefahren wird. Zwar haben wir bereits mittels doppelter Komprimierung für eine recht eingeschränkte Signaldynamik gesorgt. Doch das Lautstärkeempfinden ist bei verschiedenen Tonhöhen höchst subjektiv. Dazu kommt, dass ein Kompressor nicht zwischen solchen Parts und Stellen unterscheiden kann, die sinntragend, (klang )ästhetisch wertvoll oder sonstwie wichtig für einen Track erscheinen oder doch eher belanglos sind. Deshalb ist eine Pegel-Automation oftmals unumgänglich, wenn die Vocals wie aus einem Guss wirken sollen.
Hierfür kann natürlich ein Controller eingesetzt werden. Ich persönlich stehe allerdings mehr auf das manuelle Einzeichnen der Automationspunkte. Für den Screenshot habe ich die Y-Achse der Automations-Unterspur stark vergrößert, so dass deutlicher wird, mit welcher Strategie ich die Automationsdaten geschrieben habe. Am Ende von gehaltenen Tönen habe ich die Lautstärke vielfach angehoben. Auf diese Weise klingt der Gesang sehr “direkt” und im Mix geht später kaum Information verloren. Bei “wuchtiger” klingenden Stellen habe ich die Lautstärke zurückgefahren. Atemgeräusche habe ich weitgehend im Material belassen und an einigen Stellen sogar deutlich hervorgehoben. Die Vocals machen nun einen nochmals deutlich kompakteren Eindruck, ohne dass wir jedoch die Signaldynamik weiter einschränken mussten.
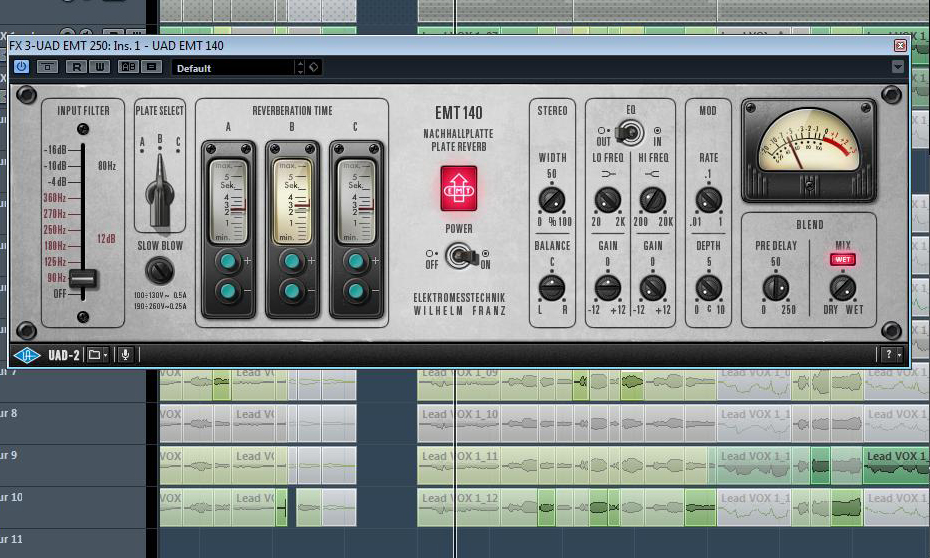
Weiter geht es mit der Räumlichkeit. Dazu greife ich in einem Send-/Effektkanal auf die UAD-Version des EMT 140-Reverbs zurück. Dabei handelt es sich um die Emulation eines klassischen Plattenhalls. Eine Nachhallzeit von rund der Sekunden soll für ausreichende “Tiefe” sorgen. Frequenzanteile unterhalb von 90 Hz (die unser Signale eigentlich sowieso nicht mehr enthalten sollte) bleiben durch den Input-Filter des EMT 140 vom Hallgerät unberücksichtigt. Die Stereoweite des Effekts setze ich auf “100%”, um maximale “Breite” zu bewirken. Eine lange Pre-Delay-Dauer soll für eine ausreichende Entkopplung des Reverb-Sounds vom Originalsignal sorgen. Da ich den Plattenhall als Send-Effekt einsetze, wähle ich im “Mix”-Bereich für das Ausgangssignal des Plug-Ins die Einstellung “Wet”. Den Effekt steuere ich über den Send-Weg des Lead-Vocal-Kanals mit einem Pegel von -24 dBFS an. Das ist ausreichend, um den Hall-Effekt im Gesamtsound deutlich ausmachen zu können. Zugleich ist dieser Send-Pegel aber auch gering genug, als dass unsere Vocals nicht im Hall versinken.
Etwas weniger zurückhaltend bin ich beim Einsatz des nächsten Send-Effekts. Hier steuere ich das Cubase-StereoDelay mit einem Send-Pegel von -19 dBFS an. Das Delay selbst ist zeitlich auf Viertelnoten gesynct, damit das Vocal-Delay unseren Track auch rhythmisch unterstützt. Auch hier wähle ich mit dem Wert “100%” im Bereich “Mix” (“Wet Only”) wiederum ausschließlich das bearbeitete Signal für den Ausgang des Plug-Ins. Die Stereosiganlanteile des Delays lenke ich extrem zu beiden Seiten aus, um den maximalen Stereoeffekt zu bewirken. Das Delay-Feedback wähle ich relativ hoch. Dadurch erhalten wir viele Delay-Stufen. Low-Cut- und High-Cut-Filter des Plug-Ins sorgen dafür, dass das Delay ausschließlich Anteile des Vocal-Signals berücksichtigt, die zwischen 150 Hz und 2 kHz liegen. So verhindern wir zum einen Rumpeln und Zischen im Delay-Kanal. Zum anderen werden unsere Vocals auf diese Weise in demjenigen Frequenzbereich gestärkt, der für gewöhnlich für “Wärme” und “Fülle” des Gesangs zuständig ist.
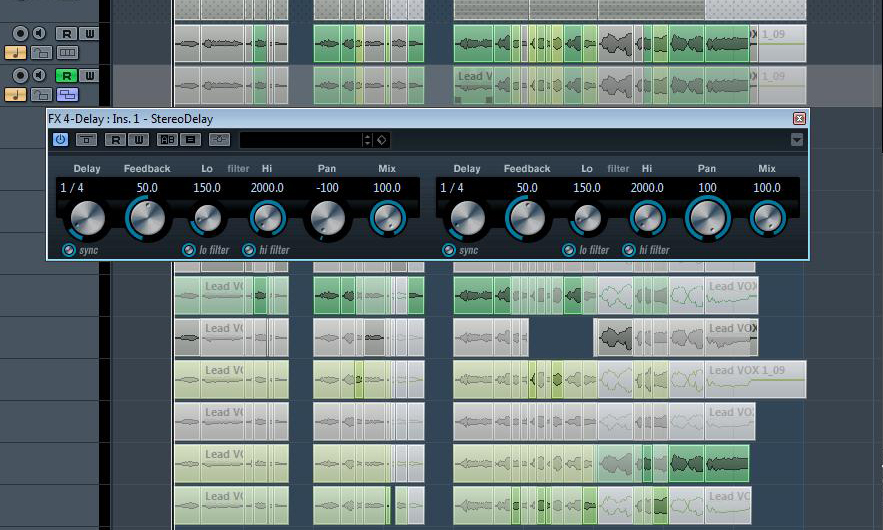
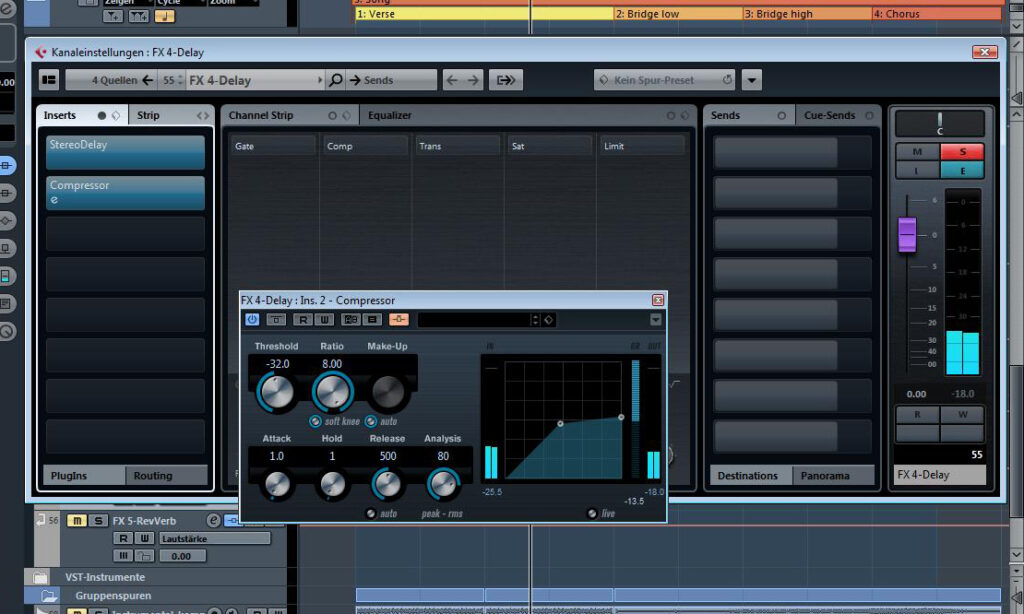
Wie das Audiobeispiel zeigt, erzeugen die Delays bei dieser Feedback-Einstellung zwar eine gehörige klangliche Tiefe, allerdings stören sie auch das Originalsignal und vermatschen es geradezu. Aus diesem Grund greife ich nun zu einem kleinen Trick: Im Kanal des Delay-Effekts füge ich im Insert-Slot hinter dem StereoDelay einen Kompressor ein, dessen Sidechain-Eingang ich aktiviere. Mit einem hohen Kompressionsverhältnis von 8:1, einer geringen Attack- und einer recht langen Releasezeit sorge ich für ein rigoroses Eingreifen des Kompressors, sobald ein Signal auf seinen Eingang trifft. Auf diesen route ich nun ein Send-Signal der Lead-Vocals mit hohem Pegel (0 dBFS). Wann immer nun das Originalsignal der Lead-Vocals zu hören ist, wird das erzeugte Delay per Ducking-Effekt des Kompressors abgesenkt. Das führt dazu dass ausschließlich dann das Delay zu hören ist, wenn die Lead-Vocals aussetzen. Auf diese Weise kommen sich Originalsignal und Delay nicht länger in die Quere. Jetzt können wir uns das resultierende Audiobeispiel anhören und stellen fest, dass der Sound unserer Lead-Vocals durch diesen Bearbeitungsschritt deutlich komplexer und vielschichtiger geworden ist.
Final Touch
Wie bei den bisherigen Vocal Production-Workshops habe ich auch diesmal wieder eine auf die Schnelle gemasterte Abschlussversion unseres Song-Snippet erstellt. Der weiterführende “Vocal Glamour”-Workshop zu diesem Vocal-Track erweitert unsere Gesangsproduktion um Backing Vocals und Produktionseffekte. Wer also erfahren möchte, wie sich unsere House-Vocals noch weiter ausbauen lassen und unterstützt werden können, so dass sie noch interessanter, professioneller und “voller” klingen, der sollte keinesfalls den noch folgenden Workshop “Vocal Glamour (House)” verpassen.
Wie gewohnt, möchte ich auch dieses Mal wieder schauen, was schlichtweg im Rahmen dieser Snippet-Produktion nicht umsetzbar war, was unseren Vocals noch fehlt und was wir hätten besser machen können. Man muss nicht allzu genau hinhören, um hier und da deutliche Artefakte festzustellen, die durch eine bessere oder nachträgliche Auswahl geeigneter Vocal-Events hätten vermieden werden können. Im Gesamtsound werden diese Störgeräusche allerdings vom “fetten” Backgroundsound zu einem großen Teil maskiert. Sicher ist es möglich, etliche weitere Lead Vocal-Takes aufzuzeichnen, um eine weitaus größere Auswahl für das Editing zu erhalten. Dabei besteht jedoch auch immer die Gefahr, sich zu verzetteln und den Überblick zu verlieren.
Performance-technisch hätten wir uns näher am Original ausrichten können, aber auch genauso gut eine weitaus eigenständigere Interpretation wagen können. Das ist letztlich natürlich Geschmackssache. Was die Produktion und den Mix der Vocals angeht, könnte es nicht schaden, das Gain Staging innerhalb der Insert-Effekt-Kette besser im Auge zu behalten. Hierauf bin ich in dieser Folge nicht eingegangen. Problematisch wird das beispielsweise beim Einsatz des Oxford-EQs, mit dessen Hilfe wir viele Frequenzbereiche abgesenkt haben. Er bietet keine Aufholverstärkung, so dass uns an dieser Stelle im Insertweg Arbeitspegel verloren geht, den wir vor dem Eingang des ersten Kompressors besser hätten ausgleichen sollen.
Hinsichtlich der Tonhöhenkorrektur wäre es denkbar, die bereits ausgebesserten Vocals noch mal mittels eines Pitch-Correction-Tools sanft weiter an eine “perfekte” Tonhöhe anzugleichen (z. B. mithilfe von Antares AutoTune oder Yamaha Pitch Fix). Wer mag, kann auch den ADT-Effekt wesentlich deutlicher einsetzen, so dass die Stimme weitaus breiter wird und so im Mix mehr Raum einnimmt. Was mir aber vor allem auffällt ist, dass der Delay-Einsatz in unserer Aufnahme noch viel zu dezent ist. Hier hätte durchaus mehr Gas gegeben werden können. Und solange Backing Vocals fehlen, darf eine einzelne Gesangsstimme wohl auch noch etwas lauter sein als im Abschluss-Track dieser Workshop-Folge. Hier empfiehlt es sich immer auch einen “Vocal Up”-Export anzulegen, in dem die Vocals mit weiteren +1 bis +1,5 dB etwas prominenter gefeaturet werden. Ich habe, ehrlich gesagt, den Fader der Vocal-Gruppenspur auf -2 dB geregelt, was eventuell eine etwas zu “defensive” Taktik war. Aber schließlich brauchen wir auch noch etwas Mix-Raum, den wir im weiterführenden “Vocal Glamour”-Workshop mit Backing Vocals ausfüllen wollen.
Viel Spaß beim Ausprobieren!
Recording-Kette: Golden Age Project TC-1, Focusrite Liquid Saffire 56 (Preset “NewAge1”)
Vocals: Lisa Bacht
























Der Mox sagt:
#1 - 12.09.2013 um 20:59 Uhr
Äußerst interessant! Vor allem, die Idee mit dem Kompressor (mit Sidechain) hinter dem Delay! Hätte man selber drauf kommen können. Aber so isses perfekt!
Am besten finde ich, dass der Autor hinterher sagt, was man hätte besser machen können. Wenn man sich das erstmal anhört, denkt man nicht an solche "Fehler". Hinterher gibt man ihm aber recht (sofern man das nachvollziehen kann) und kommt so vielleicht noch einen Schritt näher zum "perfekten" Ergebnis. Richtig Stark!!!
Octa sagt:
#2 - 27.11.2013 um 03:14 Uhr
Killer Workshop! *_*
Markus Galla sagt:
#3 - 06.03.2014 um 18:27 Uhr
Besser machen hätte man in erster Linie schon die Aufnahme und das Producing. So ist z. B. der Auslaut bei "I'm talking loud" nicht zu hören oder wurde fälschlicherweise (so klingt es fast) weggeschnitten. Man hört nur "lou" ohne den "d"-Laut.