Sampling – Einige Grundlagen aus der Digitaltechnik
Im ersten Teil unseres Specials werden wir der Digitaltechnik ein wenig auf die Pelle rücken und damit ein paar grundsätzliche Fragen beantworten. Wie digitalisiert man nun eigentlich ein analoges Audiosignal möglichst verlustfrei? Hierzu stellt der fachwissende Audiophile schon direkt die anschließende Frage: Geht das überhaupt?
Wertekontinuität
Nun, um auf diese Frage eingehen zu können, muss man wissen, wie der Sampling-Vorgang in etwa funktioniert und wo konkret die Unterschiede zwischen dem analogen Original und der digitalen Aufzeichnung liegen. Prinzipiell ist ein analoges Audiosignal eine sich über die Zeit ändernde Wechselspannung, welche von Lautsprechern oder Kopfhörern in hörbaren Schall gewandelt wird. Dabei darf diese Spannung einen gewissen Höchstwert nicht überschreiten, um den analogen Signalweg nicht zu „übersteuern“. Innerhalb dieses vorgegebenen Bereiches ist die Auflösung unendlich groß. Das bedeutet theoretisch, dass ich die grafische Darstellung der ermittelten Spannungswerte über die Zeit mit einer „Lupe“ unendlich vergrößern könnte: Es existiert zu jedem beliebigen Zeitwert ein entsprechender Spannungswert. Diese Eigenschaft bezeichnet man als Wertekontinuität.
Mit diesem Merkmal kann ein digitales File nicht mehr aufwarten, denn nach einem Digitalisierungsvorgang existieren je nach gewählter Bittiefe eine begrenzte Anzahl an entsprechenden Werten. Nehmen wir mal die Audio-CD als Beispiel: Wir erhalten bei einer Bitauflösung von 16 Bit insgesamt 65.536 mögliche Werte. Bei einer Aufnahme in 24 Bit sieht das schon ganz anders aus, denn hier stehen uns bereits 16.777.216 mögliche Abtastwerte zur Verfügung. Es folgen ein paar Audiobeispiele zur Veranschaulichung (Hinweis: Alle Audios kann man am Ende des Artikels als .wav-Files downloaden).

Grundsätzlich lässt sich zu dieser Thematik folgendes sagen:
1. Je größer die Bittiefe einer digitalen Aufnahme, desto besser ist der darstellbare Dynamikumfang. Darüber hinaus vergrößert sich der Signal-Rauschspannungsabstand.
2. Die Bitauflösung einer Audio-CD (16 Bit) eignet sich hervorragend für Konsumenten-Zwecke, aber auch für (semi)professionelle Aufnahmen, wenn keine abschließende Soundbearbeitung mehr erfolgt.
3. Für die Aufzeichnung von Musik oder Sprache eignen sich Wortbreiten von 18 bis 24 Bit insbesondere dann, wenn die Aufnahmen danach noch bearbeitet werden.
4. Auf geringere Bittiefen als 16 Bit sollte bei Endprodukten nur dann zurückgegriffen werden, wenn
a)…die Datei möglichst klein sein soll (Streaming, Download etc.) oder
c)…es sich um eine Preview handelt, die schnell verschickt werden soll oder
c)…aufgrund von Lizenzrechten keine Originalqualität bereitgestellt werden darf.
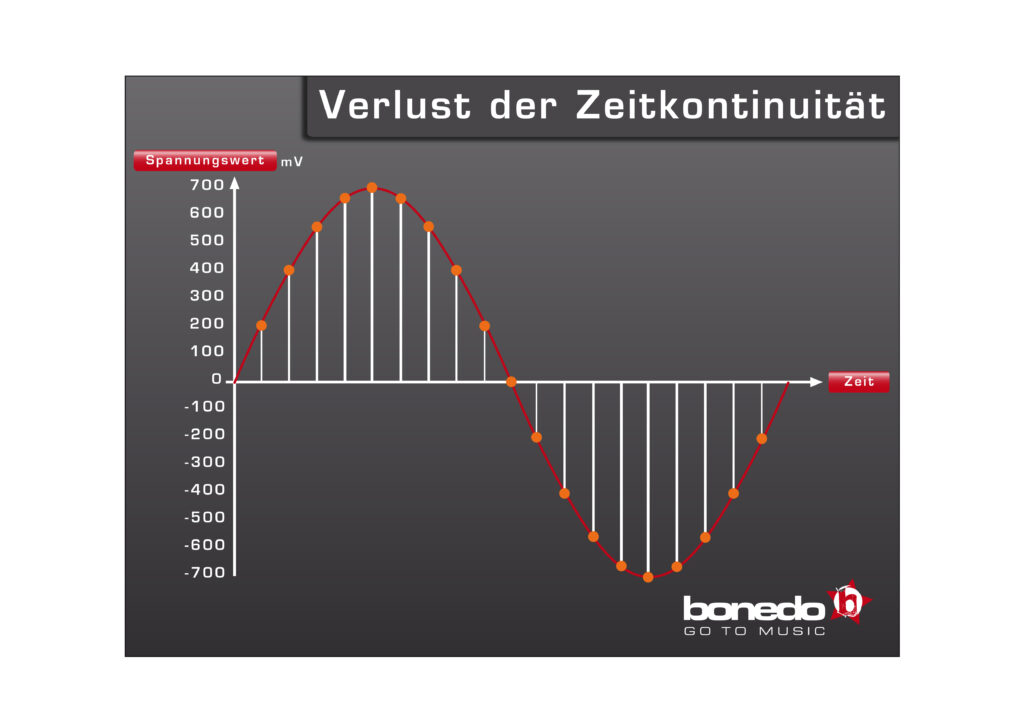
Zeitkontinuität
Die Aufnahme einer analogen Bandmaschine ist zeitkontinuierlich, was ihr einen kleinen Vorteil gegenüber einer digitalen Samplingstufe verschafft. Zeitkontinuität bedeutet, dass man zu jedwedem Wert auf der Zeitachse einen entsprechenden Spannungswert finden kann. Die digitalisierte Wechselspannung hingegen hat die Eigenschaft der Zeitkontinuität beim Übergang in die digitale Welt verloren, denn, nehmen wir wieder die Audio-CD als Maßstab, existieren in dem aufgenommenen File nur noch 44100 Werte pro Sekunde (44,1 kHz = Sampling-Frequenz einer Audio-CD).
Produktion im Zielformat
Doch was bringen uns diese Erkenntnisse? – Nun, grundsätzlich könnte man sagen, dass man der Eigenschaft der Zeitkontinuität so nahe wie möglich kommen sollte, sprich bei der Aufnahme und Produktion möglichst hohe Sampling-Frequenzen nutzt. Doch Vorsicht: Der Teufel steckt auch hier im Detail. Die Hersteller von Audioschnittstellen bieten bei hoch getakteten Audio-Interfaces meist folgende mögliche Sampling-Frequenzen für eine Session an:
44,1 kHz
48,0 kHz
88,2 kHz
96,0 kHz
176,4 kHz
192,0 kHz
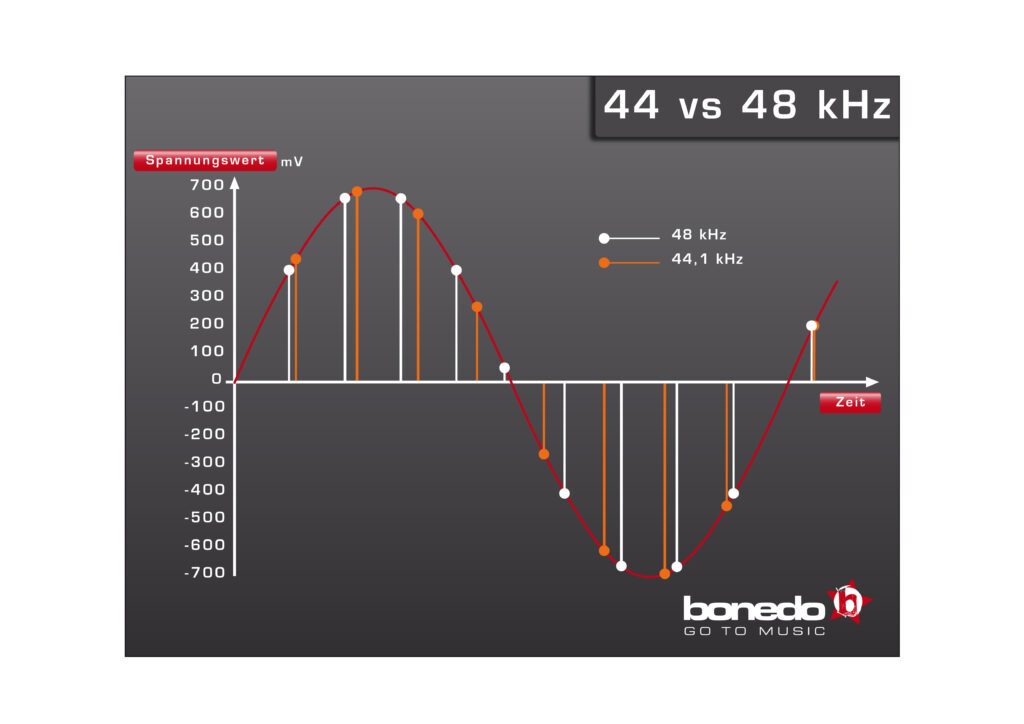
Nun, daraus ergibt sich die nächste Frage: Habe ich ein Audio-Interface, welches maximal 192 kHz unterstützt, sollte ich dann meine Gesangsaufnahmen auch mit 192000 Hz aufnehmen? – Die Antwort hierauf ist zunächst „Nein“. Vorher sollte man in diesem Zusammenhang die Sampling-Frequenz des Zielformates in Erfahrung bringen. Nehmen wir mal an, das Endformat sei die Audio-CD, die ausschließlich 44,1 kHz unterstützt. Wenn der Hörer von Audio-CDs also die Zielgruppe darstellt, empfiehlt sich, das Zielformat selbst oder eben ganzzahlige Vielfache davon, also 88,2 oder 176,4 kHz. Der Grund hierfür ist folgender: Bei der Umrechnung von ganzzahligen Vielfachen ist der Algorithmus hierfür relativ einfach strukturiert. Bei der Konvertierung von 88,2 kHz auf 44,1 kHz wird einfach nur jeder zweite Wert genutzt und bei 176,4 kHz nur jeder vierte. Wie man sich vorstellen kann, ist diese Art der Konvertierung relativ einfach zu realisieren. Man reduziert einfach die Menge an Werten. Das Audio-File ist nicht mehr so hoch aufgelöst, für den reinen Konsum aber allemal ausreichend. Die Probleme tauchen auf, wenn die Samplingfrequenzen kein ganzzahliges Verhältnis zueinander haben.
Woher kommt eigentlich die 48 kHz als mögliche Sampling-Frequenz? Wie so oft müssen die Broadcaster offenbar ihr „eigenes Süppchen kochen“. In der EBU (European Broadcasting Union) einigten sich die relevanten Sendehäuser Europas einst auf 48 kHz als professionelle Samplingfrequenz, um den Austausch von Beiträgen zwischen den Sendeanstalten zu standardisieren und somit zu vereinfachen. Die Abtastrate 48 kHz kommt also aus der Broadcast-Technik und ist dort auch heute noch aktuell. Sobald aber gewechselt wird, tauchen Probleme auf, die zwar technisch lösbar sind, aber immer mit Qualitätsverlusten einhergehen.
Wenn zum Beispiel Musikdateien aus der Musikproduktion bei Broadcastern wie Musiksendern oder Radiostationen angeliefert werden, müssen die Dateien vorher konvertiert werden. Es werden neue Files erstellt, die dann über die erforderliche Abtastrate von 48 kHz verfügen. Dieser Vorgang und der hierfür verwendete Algorithmus gestaltet sich ein wenig komplizierter, denn man kann hier nicht einfach jeden zweiten Wert weglassen, sondern die Konvertierungs-Software interpoliert einige Werte, da ja 1,088 mal so viele Werte zur Verfügung stehen (48:44,1 = 1,088).
Highend
Bei einer Produktion für High-End-Kunden sollte man generell kompromisslos vorgehen. Hier wäre z.B. das Zielformat BlueRay zu nennen, welches immerhin Abtastraten bis zu 192 kHz und Bittiefen bis zu 24 Bit unterstützt. Mit der konventionellen “PCM”-Technik kann man für diese High-End-Kunden produzieren, indem man mit einer Auflösung von 24 Bit und 192 kHz arbeitet. Die Down-Konvertierung für die Audio-CD am Ende der Produktionskette ist dabei problemlos möglich, aber verlustbehaftet.
Hohe Qualität vs. Datenaufkommen
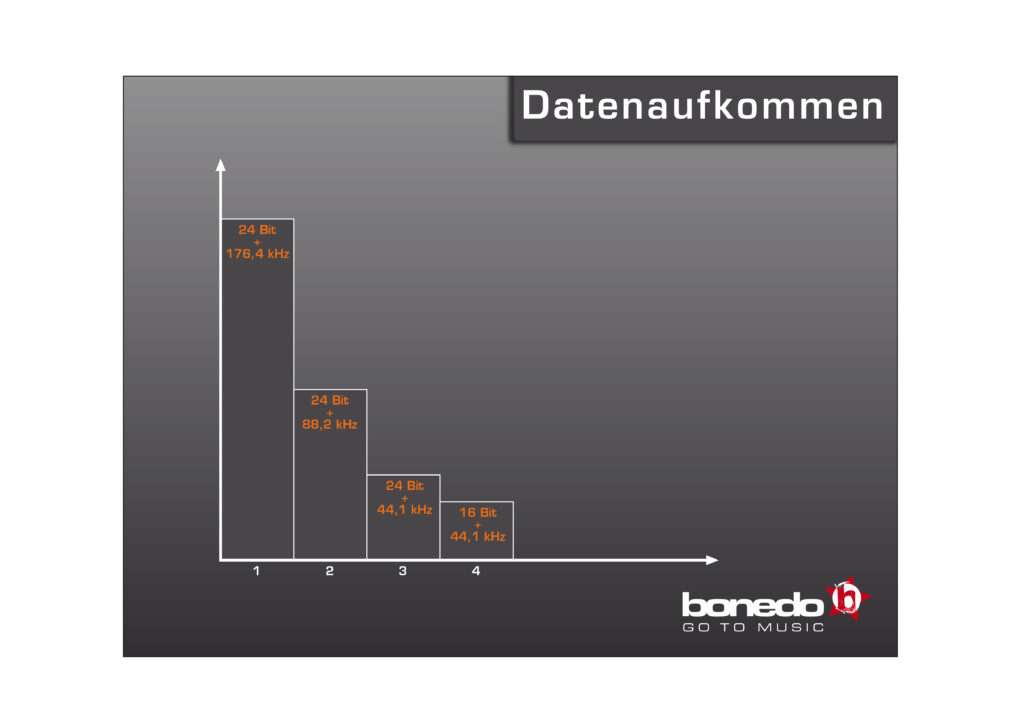
Kommen wir nun zur Kehrseite hoher Datenraten, die durch erhöhte Samplingraten oder Bit-Auflösungen verursacht werden. Wer seine Session von Beginn an in 24 anstatt in 16 Bit anlegt, hat ein 1,5-faches Datenaufkommen. Hierbei geht es um den bloßen Speicherplatzbedarf, weniger um die Lesegeschwindigkeit der Laufwerke. Aktuelle Festplatten, respektive SSD-Laufwerke sollten bei 24-Spur-Produktionen keine Mucken machen. Wer also schnelle Harddiscs verwendet, muss nur zusehen, dass er genügend Platz auf dem Datenträger hat.
Die zweite Variable, die Abtastrate, wirkt sich schon ein wenig dramatischer aus. Beim Upgrade von 44,1 auf 88,2 kHz erhöht sich diese um den Faktor „2“. Bei High End-Produktionen mit 176,4 kHz ist das Datenaufkommen viermal so hoch. Stellt man nun einen Vergleich an, bei dem man gleichzeitig an beiden Variablen schraubt, sprich 24 Bit und 176 kHz verwendet, ist das Volumen sechsmal höher als bei einer Audio-CD! Ein Track, der auf der Audio-CD etwa 60 MB beansprucht, ist vor der Down-Konvertierung dementsprechend 300 MB groß; und wir reden hier nur vom Master und nicht von den Einzelspuren einer Produktion!
Es folgen ein paar Audiobeispiele, bei denen ich die Samplingfrequenzen reduziert habe. Zum einen Standard-Samplefrequenzen wie 44,1 und 32 kHz, aber auch 22,050 und 11,025 kHz. Letztere habe ich anschließend wieder auf 44,1 kHz hochgerechnet, weil sie von den meisten Soundkarten standardmäßig nicht unterstützt werden. So könnt ihr etwa nachvollziehen, was passiert, wenn an der Samplingrate „gespart“ wird – die Bandbreite verringert sich deutlich hörbar.
Erhöhte Sample-Frequenz in der Produktion – Warum?
Ein praktisch denkender Mensch wird sich zu Beginn einer Produktion die Frage stellen: Wieso soll ich meine Produktion in 88,2 kHz anstatt in 44,1 kHz durchführen, wenn ich beim Download-Portal sowieso ein File mit 44,1 kHz abliefern muss? Im Prinzip hätte er nicht Unrecht, doch hat er das Thema nicht bis ins Detail zu Ende gedacht: Nehmen wir mal an, wir produzieren einen Song, bei dem insbesondere akustische Aufnahmen die Grundlage bilden. Allein die Wiedergabequalität ist nach der Aufnahmephase doppelt so hoch aufgelöst wie normal. „Insbesondere die hohen Frequenzen werden es danken“, sagt der audiophil geneigte Zuhörer. Doch warum? Nun, bei 44,1 kHz Abtastrate hätten wir für die digitale Wertegewinnung bei einer Schwingung von 20 kHz nur 2,2 Werte für die Darstellung zur Verfügung (44,1:20 = 2,2). Das ist mal vornehm ausgedrückt, ziemlich wenig, um einen Schwingungsdurchlauf konkret nachzuzeichnen. Ein Sinuston würde wie eine Rechtecksschwingung aussehen. Bei 88,2 kHz Abtastrate hätten wir immerhin schon 4,5 Werte und bei 176,4 kHz sind es 9, mit denen wir eine 20-kHz-Sinusschwingung darstellen können.


Das Problem wirkt sich schon nur beim Hören unter Idealbedingungen aus. Man kann sich vorstellen, was ein virtueller Equalizer dann mit der im Prinzip unterabgetasteten 20-kHz-Sinusschwingung anstellt. Das Signal hat im Grunde im hohen Frequenzbereich nach dem EQ-Edit nichts mehr mit dem Original zu tun. Bei einer Mehrspurproduktion summieren sich diese Fehler beim Bearbeiten und auch beim Mixvorgang, sprich der virtuellen Überlagerung der Einzelsignale, so dass die Summe anschließend lauter kleine Fehler beinhaltet. Daher wird bei Mehrspurproduktionen, die akustische Aufnahmen verwenden, empfohlen, mindestens mit 88,2 kHz zu produzieren, insbesondere dann, wenn anschließend frequenzselektive Bearbeitungen durchgeführt werden. Erst am Ende wird das Master auf die Qualität der Audio-CD heruntergerechnet. Dieser Weg führt immer zu dem besseren Ergebnis!
Ein weiterer wichtiger Grund für die Nutzung von hohen Samplerates ist die Tatsache, dass die verwendeten Lowpass-Filter in der Sample-Stufe mit geringerer Güte und somit weniger steilflankig arbeiten können und dadurch deutlich weniger hörbare Probleme verursachen.
Hinsichtlich der Sampling-Frequenz lassen sich für die Produktion folgende Aussagen treffen:
1) Je höher die Sampling-Frequenz, desto besser ist die Wiedergabequalität insbesondere bei hohen Frequenzen.
2) Je höher die gewählte Abtastrate ist, desto größer ist der darzustellende Frequenzbereich (> 20.000 Hz).
3) Bei Bearbeitungen, wie etwa bei der Verwendung von digitalen Equalizern, kommt man bei höheren Abtastraten zu besseren klanglichen Ergebnissen.
4) Bei der Verwendung von höheren Abtastraten sollten nach Möglichkeit nur ganzzahlige Vielfache der Zielfrequenz genutzt werden. Also bei 44,1 kHz -> 88,2 und 176,4 kHz und bei 48,0 kHz -> 96 und 192 kHz.
5) Die Sampling-Frequenz 44,1 kHz eignet sich sehr gut für die Archivierung, bzw. den Konsum von Musik
6) Auf geringere Abtastraten als 44,1 kHz sollte bei Endprodukten nur dann zurückgegriffen werden, wenn…
a)…die Datei möglichst klein sein soll (Streaming, Download etc.) oder
b) …es sich um eine Vorschau handelt, die schnell verschickt werden soll oder
c)…aufgrund von Lizenzrechten keine Originalqualität bereitgestellt werden darf
Uncompressed – Nomen est Omen?
“Unkomprimiert” wird als Synonym für „verlustfrei“ verwendet. Doch stimmt das wirklich? – Nun, korrekterweise ist “uncompressed” ein „Audioformat“, welches aus dem PCM-Verfahren gewonnen wird. PCM ist die Abkürzung für Puls-Code-Modulation und bezeichnet ein Verfahren, welches mittels Pulsamplitudenmodulation ein analoges in ein digitales Signal wandelt. Bei diesem Sample-Vorgang verliert dieses, wie schon anfangs erwähnt, seine wertvollen Eigenschaften „Werte- und Zeitkontinuität“. Egal, mit wie vielen Abtastwerten und mit welcher Bit-Tiefe auch immer gearbeitet wird, der Wertevorrat ist beschränkt (bei 16 Bit sind es 65536 mögliche Werte) und die zeitliche Auflösung ebenfalls (44100 Werte pro Sekunde bei 44,1 kHz Sampling-Frequenz). Von uncompressed spricht man in der Regel bei Aufnahmen mit mindestens 8 Bit und 22,05 kHz. Hierfür kommen die Audio-File-Formate WAV und AIFF in Frage.
Datenreduktion vs. Datenkompression?
Im Grunde versteht man unter Datenkompression die Verdichtung digitaler Daten ohne einen Qualitätsverlust. Die vor der Übertragung entfernten Informationen werden anschließend vollständig wiederhergestellt – ein frommer Wunsch, wie wir noch sehen werden. Unter der Datenreduktion versteht man die Verminderung der Datenmenge nach einem verlustbehafteten Algorithmus. Die Daten sind nach der Übertragung zwar unwiderruflich verloren, müssen aber subjektiv nicht zu einer Verschlechterung des Materials führen, auch wenn es objektiv betrachtet definitiv anders, also messbar ist.
Da in der Videotechnik aufgrund sehr hoher Datenaufkommen das Bedürfnis nach Verminderung der Datenraten sehr groß ist, wird hier meist eine Kombination aus Datenreduktion und Datenkompression betrieben. Dieses Bedürfnis ist bei den „Audioten“ zumindest in professionellen Arbeitsumgebungen nicht so groß. Sobald Audiomaterial in den gängigen Uncompressed-Formaten aufgezeichnet oder angeliefert wird, spricht man hier von nicht datenreduziertem Material. Neben den Uncompressed-Formaten gibt es einige Audio-File-Formate, welche eine verlustbehaftete Datenreduktion anwenden. Hierzu zählen: AAC, AC-3, DTS, MP3, WMA und OGG Vorbis. Zu den verlustfreien Datenkompressionsverfahren zählen unter anderem MLP (SACD) und DOLBY True HD, DTS-HD, FLAC, AIAC und Wavack. Mehr dazu in Teil 2…
Hier könnt ihr noch – wie versprochen – alle Audiofiles als ZIPs downloaden:

























Jan sagt:
#1 - 12.06.2012 um 19:09 Uhr
Irgendwie fehlt, dass die Samplingrate mehr als das doppelte der höchsten zu abtasten gewünschten Frequenz sein muss.
Das schwingt nur so indirekt im Text mit. 44kHz -> höchste Frequenz die ich aufnehmen kann ist also um die 20kHz.
Dies ist nötig da sonst die originale Frequenz bei der Wiedergabe nicht wiederherstellbar ist.
Mehr infos: Nyquist-Shannon-AbtasttheoremSonst ein wirklich guter Artikel :) bin gespannt auf den Codec Teil :)
Daniel Wagner sagt:
#2 - 27.06.2012 um 16:31 Uhr
Wir haben absichtlich nicht über das Abtasttheorem geschrieben, um den Artikel so einfach wie möglich zu halten. Es geht in diesem Fearure um praxisdienliche Hinweise, bzw. um Leitssätze, an die man sich hält, wenn man produziert, und nicht um eine vollständige Klärung des theoretischen Hintergrunds. Wer mehr wissen möchte, kann in unserem "Radikal Digital"-Feature mehr Infos bekommen. Darüber hinaus sind für die Zukunft noch mehr Features zu diesem Thema geplant..
..Greetz
Alex Abedi sagt:
#3 - 01.06.2015 um 11:30 Uhr
An diesem Thema scheiden sich die Götter. Das Audiomaterial wird jedenfalls nicht besser "aufgelöst" bei höherer Bitrate sondern, lediglich erhöht sich die Bandbreite.
Ich bleibe bei 44.1 Khz bei Highendproduktionen. :)
Nick (Redaktion Recording) sagt:
#3.1 - 01.06.2015 um 11:57 Uhr
Hi Alex,danke für Deinen Beitrag.Du meinst Samplerate, oder? Höhere Bitrate löst ja in der A/D-Wandlung die analoge Spannung weiter auf, was sich besonders für die Dynamik (Rauschspannungsabstand, Aussteuerbarkeit/Headroom…) positiv auswirkt. Insofern sind 24 Bit eigentlich immer vorteilhaft. Doppelte, vier- oder gar achtfache Samplerates sind allerdings wirklich ein vieldiskutiertes Thema. Es gibt zwar wirklich eine Reihe Pro-Argumente (Bandbreite, Darstellung von Impulsen/Transienten, mögliche Bearbeitung in der digitalen Domäne…), aber eben auch einige Cons (Datenmengen, Fehleranfälligkeiten…). Und die Qualität gerade von Wandlern hängt ja nicht von einer Geschwindigkeit ab. Es gibt verdammt gute 44,1/48kHz-Wandler und wirklich schwache 192kHz-ADCs.Beste Grüße,
Nick (Redaktion Recording)
Antwort auf #3 von Alex Abedi
Melden Empfehlen Empfehlung entfernenAlex Abedi sagt:
#3.1.1 - 01.06.2015 um 21:42 Uhr
Hi Nick,vielen Dank für die tolle Antwort. Ich denke auch dass die Bitrate wichtiger ist als die Samplerate. Ich habe ein paar Projekte in 88,2 Khz gefahren und habe mich bei dem konvertieren in 44.1 Khz immer aufgeregt, weil ich da die "gewonne" Qualität wieder verloren habe. Deswegen mache ich es mir einfach, und bleibe bei 44.1 Khz. Die Produktionen klingen jedenfalls nicht schlecht.Lieben GrußAlex
Antwort auf #3.1 von Nick (Redaktion Recording)
Melden Empfehlen Empfehlung entfernen